mirror of
https://github.com/Raghu-Ch/nodeRestAPI.git
synced 2026-02-10 12:43:02 -05:00
initial commit
This commit is contained in:
15
node_modules/readdirp/.npmignore
generated
vendored
Normal file
15
node_modules/readdirp/.npmignore
generated
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
lib-cov
|
||||
*.seed
|
||||
*.log
|
||||
*.csv
|
||||
*.dat
|
||||
*.out
|
||||
*.pid
|
||||
*.gz
|
||||
|
||||
pids
|
||||
logs
|
||||
results
|
||||
|
||||
node_modules
|
||||
npm-debug.log
|
||||
6
node_modules/readdirp/.travis.yml
generated
vendored
Normal file
6
node_modules/readdirp/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
language: node_js
|
||||
node_js:
|
||||
- "0.10"
|
||||
- "0.12"
|
||||
- "4.4"
|
||||
- "6.2"
|
||||
20
node_modules/readdirp/LICENSE
generated
vendored
Normal file
20
node_modules/readdirp/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
This software is released under the MIT license:
|
||||
|
||||
Copyright (c) 2012-2015 Thorsten Lorenz
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
||||
this software and associated documentation files (the "Software"), to deal in
|
||||
the Software without restriction, including without limitation the rights to
|
||||
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
||||
the Software, and to permit persons to whom the Software is furnished to do so,
|
||||
subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
||||
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
||||
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
||||
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
||||
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
233
node_modules/readdirp/README.md
generated
vendored
Normal file
233
node_modules/readdirp/README.md
generated
vendored
Normal file
@@ -0,0 +1,233 @@
|
||||
# readdirp [](http://travis-ci.org/thlorenz/readdirp)
|
||||
|
||||
[](https://nodei.co/npm/readdirp/)
|
||||
|
||||
Recursive version of [fs.readdir](http://nodejs.org/docs/latest/api/fs.html#fs_fs_readdir_path_callback). Exposes a **stream api**.
|
||||
|
||||
```javascript
|
||||
var readdirp = require('readdirp')
|
||||
, path = require('path')
|
||||
, es = require('event-stream');
|
||||
|
||||
// print out all JavaScript files along with their size
|
||||
|
||||
var stream = readdirp({ root: path.join(__dirname), fileFilter: '*.js' });
|
||||
stream
|
||||
.on('warn', function (err) {
|
||||
console.error('non-fatal error', err);
|
||||
// optionally call stream.destroy() here in order to abort and cause 'close' to be emitted
|
||||
})
|
||||
.on('error', function (err) { console.error('fatal error', err); })
|
||||
.pipe(es.mapSync(function (entry) {
|
||||
return { path: entry.path, size: entry.stat.size };
|
||||
}))
|
||||
.pipe(es.stringify())
|
||||
.pipe(process.stdout);
|
||||
```
|
||||
|
||||
Meant to be one of the recursive versions of [fs](http://nodejs.org/docs/latest/api/fs.html) functions, e.g., like [mkdirp](https://github.com/substack/node-mkdirp).
|
||||
|
||||
**Table of Contents** *generated with [DocToc](http://doctoc.herokuapp.com/)*
|
||||
|
||||
- [Installation](#installation)
|
||||
- [API](#api)
|
||||
- [entry stream](#entry-stream)
|
||||
- [options](#options)
|
||||
- [entry info](#entry-info)
|
||||
- [Filters](#filters)
|
||||
- [Callback API](#callback-api)
|
||||
- [allProcessed ](#allprocessed)
|
||||
- [fileProcessed](#fileprocessed)
|
||||
- [More Examples](#more-examples)
|
||||
- [stream api](#stream-api)
|
||||
- [stream api pipe](#stream-api-pipe)
|
||||
- [grep](#grep)
|
||||
- [using callback api](#using-callback-api)
|
||||
- [tests](#tests)
|
||||
|
||||
|
||||
# Installation
|
||||
|
||||
npm install readdirp
|
||||
|
||||
# API
|
||||
|
||||
***var entryStream = readdirp (options)***
|
||||
|
||||
Reads given root recursively and returns a `stream` of [entry info](#entry-info)s.
|
||||
|
||||
## entry stream
|
||||
|
||||
Behaves as follows:
|
||||
|
||||
- `emit('data')` passes an [entry info](#entry-info) whenever one is found
|
||||
- `emit('warn')` passes a non-fatal `Error` that prevents a file/directory from being processed (i.e., if it is
|
||||
inaccessible to the user)
|
||||
- `emit('error')` passes a fatal `Error` which also ends the stream (i.e., when illegal options where passed)
|
||||
- `emit('end')` called when all entries were found and no more will be emitted (i.e., we are done)
|
||||
- `emit('close')` called when the stream is destroyed via `stream.destroy()` (which could be useful if you want to
|
||||
manually abort even on a non fatal error) - at that point the stream is no longer `readable` and no more entries,
|
||||
warning or errors are emitted
|
||||
- to learn more about streams, consult the very detailed
|
||||
[nodejs streams documentation](http://nodejs.org/api/stream.html) or the
|
||||
[stream-handbook](https://github.com/substack/stream-handbook)
|
||||
|
||||
|
||||
## options
|
||||
|
||||
- **root**: path in which to start reading and recursing into subdirectories
|
||||
|
||||
- **fileFilter**: filter to include/exclude files found (see [Filters](#filters) for more)
|
||||
|
||||
- **directoryFilter**: filter to include/exclude directories found and to recurse into (see [Filters](#filters) for more)
|
||||
|
||||
- **depth**: depth at which to stop recursing even if more subdirectories are found
|
||||
|
||||
- **entryType**: determines if data events on the stream should be emitted for `'files'`, `'directories'`, `'both'`, or `'all'`. Setting to `'all'` will also include entries for other types of file descriptors like character devices, unix sockets and named pipes. Defaults to `'files'`.
|
||||
|
||||
- **lstat**: if `true`, readdirp uses `fs.lstat` instead of `fs.stat` in order to stat files and includes symlink entries in the stream along with files.
|
||||
|
||||
## entry info
|
||||
|
||||
Has the following properties:
|
||||
|
||||
- **parentDir** : directory in which entry was found (relative to given root)
|
||||
- **fullParentDir** : full path to parent directory
|
||||
- **name** : name of the file/directory
|
||||
- **path** : path to the file/directory (relative to given root)
|
||||
- **fullPath** : full path to the file/directory found
|
||||
- **stat** : built in [stat object](http://nodejs.org/docs/v0.4.9/api/fs.html#fs.Stats)
|
||||
- **Example**: (assuming root was `/User/dev/readdirp`)
|
||||
|
||||
parentDir : 'test/bed/root_dir1',
|
||||
fullParentDir : '/User/dev/readdirp/test/bed/root_dir1',
|
||||
name : 'root_dir1_subdir1',
|
||||
path : 'test/bed/root_dir1/root_dir1_subdir1',
|
||||
fullPath : '/User/dev/readdirp/test/bed/root_dir1/root_dir1_subdir1',
|
||||
stat : [ ... ]
|
||||
|
||||
## Filters
|
||||
|
||||
There are three different ways to specify filters for files and directories respectively.
|
||||
|
||||
- **function**: a function that takes an entry info as a parameter and returns true to include or false to exclude the entry
|
||||
|
||||
- **glob string**: a string (e.g., `*.js`) which is matched using [minimatch](https://github.com/isaacs/minimatch), so go there for more
|
||||
information.
|
||||
|
||||
Globstars (`**`) are not supported since specifiying a recursive pattern for an already recursive function doesn't make sense.
|
||||
|
||||
Negated globs (as explained in the minimatch documentation) are allowed, e.g., `!*.txt` matches everything but text files.
|
||||
|
||||
- **array of glob strings**: either need to be all inclusive or all exclusive (negated) patterns otherwise an error is thrown.
|
||||
|
||||
`[ '*.json', '*.js' ]` includes all JavaScript and Json files.
|
||||
|
||||
|
||||
`[ '!.git', '!node_modules' ]` includes all directories except the '.git' and 'node_modules'.
|
||||
|
||||
Directories that do not pass a filter will not be recursed into.
|
||||
|
||||
## Callback API
|
||||
|
||||
Although the stream api is recommended, readdirp also exposes a callback based api.
|
||||
|
||||
***readdirp (options, callback1 [, callback2])***
|
||||
|
||||
If callback2 is given, callback1 functions as the **fileProcessed** callback, and callback2 as the **allProcessed** callback.
|
||||
|
||||
If only callback1 is given, it functions as the **allProcessed** callback.
|
||||
|
||||
### allProcessed
|
||||
|
||||
- function with err and res parameters, e.g., `function (err, res) { ... }`
|
||||
- **err**: array of errors that occurred during the operation, **res may still be present, even if errors occurred**
|
||||
- **res**: collection of file/directory [entry infos](#entry-info)
|
||||
|
||||
### fileProcessed
|
||||
|
||||
- function with [entry info](#entry-info) parameter e.g., `function (entryInfo) { ... }`
|
||||
|
||||
|
||||
# More Examples
|
||||
|
||||
`on('error', ..)`, `on('warn', ..)` and `on('end', ..)` handling omitted for brevity
|
||||
|
||||
```javascript
|
||||
var readdirp = require('readdirp');
|
||||
|
||||
// Glob file filter
|
||||
readdirp({ root: './test/bed', fileFilter: '*.js' })
|
||||
.on('data', function (entry) {
|
||||
// do something with each JavaScript file entry
|
||||
});
|
||||
|
||||
// Combined glob file filters
|
||||
readdirp({ root: './test/bed', fileFilter: [ '*.js', '*.json' ] })
|
||||
.on('data', function (entry) {
|
||||
// do something with each JavaScript and Json file entry
|
||||
});
|
||||
|
||||
// Combined negated directory filters
|
||||
readdirp({ root: './test/bed', directoryFilter: [ '!.git', '!*modules' ] })
|
||||
.on('data', function (entry) {
|
||||
// do something with each file entry found outside '.git' or any modules directory
|
||||
});
|
||||
|
||||
// Function directory filter
|
||||
readdirp({ root: './test/bed', directoryFilter: function (di) { return di.name.length === 9; } })
|
||||
.on('data', function (entry) {
|
||||
// do something with each file entry found inside directories whose name has length 9
|
||||
});
|
||||
|
||||
// Limiting depth
|
||||
readdirp({ root: './test/bed', depth: 1 })
|
||||
.on('data', function (entry) {
|
||||
// do something with each file entry found up to 1 subdirectory deep
|
||||
});
|
||||
|
||||
// callback api
|
||||
readdirp(
|
||||
{ root: '.' }
|
||||
, function(fileInfo) {
|
||||
// do something with file entry here
|
||||
}
|
||||
, function (err, res) {
|
||||
// all done, move on or do final step for all file entries here
|
||||
}
|
||||
);
|
||||
```
|
||||
|
||||
Try more examples by following [instructions](https://github.com/thlorenz/readdirp/blob/master/examples/Readme.md)
|
||||
on how to get going.
|
||||
|
||||
## stream api
|
||||
|
||||
[stream-api.js](https://github.com/thlorenz/readdirp/blob/master/examples/stream-api.js)
|
||||
|
||||
Demonstrates error and data handling by listening to events emitted from the readdirp stream.
|
||||
|
||||
## stream api pipe
|
||||
|
||||
[stream-api-pipe.js](https://github.com/thlorenz/readdirp/blob/master/examples/stream-api-pipe.js)
|
||||
|
||||
Demonstrates error handling by listening to events emitted from the readdirp stream and how to pipe the data stream into
|
||||
another destination stream.
|
||||
|
||||
## grep
|
||||
|
||||
[grep.js](https://github.com/thlorenz/readdirp/blob/master/examples/grep.js)
|
||||
|
||||
Very naive implementation of grep, for demonstration purposes only.
|
||||
|
||||
## using callback api
|
||||
|
||||
[callback-api.js](https://github.com/thlorenz/readdirp/blob/master/examples/callback-api.js)
|
||||
|
||||
Shows how to pass callbacks in order to handle errors and/or data.
|
||||
|
||||
## tests
|
||||
|
||||
The [readdirp tests](https://github.com/thlorenz/readdirp/blob/master/test/readdirp.js) also will give you a good idea on
|
||||
how things work.
|
||||
|
||||
37
node_modules/readdirp/examples/Readme.md
generated
vendored
Normal file
37
node_modules/readdirp/examples/Readme.md
generated
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
# readdirp examples
|
||||
|
||||
## How to run the examples
|
||||
|
||||
Assuming you installed readdirp (`npm install readdirp`), you can do the following:
|
||||
|
||||
1. `npm explore readdirp`
|
||||
2. `cd examples`
|
||||
3. `npm install`
|
||||
|
||||
At that point you can run the examples with node, i.e., `node grep`.
|
||||
|
||||
## stream api
|
||||
|
||||
[stream-api.js](https://github.com/thlorenz/readdirp/blob/master/examples/stream-api.js)
|
||||
|
||||
Demonstrates error and data handling by listening to events emitted from the readdirp stream.
|
||||
|
||||
## stream api pipe
|
||||
|
||||
[stream-api-pipe.js](https://github.com/thlorenz/readdirp/blob/master/examples/stream-api-pipe.js)
|
||||
|
||||
Demonstrates error handling by listening to events emitted from the readdirp stream and how to pipe the data stream into
|
||||
another destination stream.
|
||||
|
||||
## grep
|
||||
|
||||
[grep.js](https://github.com/thlorenz/readdirp/blob/master/examples/grep.js)
|
||||
|
||||
Very naive implementation of grep, for demonstration purposes only.
|
||||
|
||||
## using callback api
|
||||
|
||||
[callback-api.js](https://github.com/thlorenz/readdirp/blob/master/examples/callback-api.js)
|
||||
|
||||
Shows how to pass callbacks in order to handle errors and/or data.
|
||||
|
||||
10
node_modules/readdirp/examples/callback-api.js
generated
vendored
Normal file
10
node_modules/readdirp/examples/callback-api.js
generated
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
var readdirp = require('..');
|
||||
|
||||
readdirp({ root: '.', fileFilter: '*.js' }, function (errors, res) {
|
||||
if (errors) {
|
||||
errors.forEach(function (err) {
|
||||
console.error('Error: ', err);
|
||||
});
|
||||
}
|
||||
console.log('all javascript files', res);
|
||||
});
|
||||
71
node_modules/readdirp/examples/grep.js
generated
vendored
Normal file
71
node_modules/readdirp/examples/grep.js
generated
vendored
Normal file
@@ -0,0 +1,71 @@
|
||||
'use strict';
|
||||
var readdirp = require('..')
|
||||
, util = require('util')
|
||||
, fs = require('fs')
|
||||
, path = require('path')
|
||||
, es = require('event-stream')
|
||||
;
|
||||
|
||||
function findLinesMatching (searchTerm) {
|
||||
|
||||
return es.through(function (entry) {
|
||||
var lineno = 0
|
||||
, matchingLines = []
|
||||
, fileStream = this;
|
||||
|
||||
function filter () {
|
||||
return es.mapSync(function (line) {
|
||||
lineno++;
|
||||
return ~line.indexOf(searchTerm) ? lineno + ': ' + line : undefined;
|
||||
});
|
||||
}
|
||||
|
||||
function aggregate () {
|
||||
return es.through(
|
||||
function write (data) {
|
||||
matchingLines.push(data);
|
||||
}
|
||||
, function end () {
|
||||
|
||||
// drop files that had no matches
|
||||
if (matchingLines.length) {
|
||||
var result = { file: entry, lines: matchingLines };
|
||||
|
||||
// pass result on to file stream
|
||||
fileStream.emit('data', result);
|
||||
}
|
||||
this.emit('end');
|
||||
}
|
||||
);
|
||||
}
|
||||
|
||||
fs.createReadStream(entry.fullPath, { encoding: 'utf-8' })
|
||||
|
||||
// handle file contents line by line
|
||||
.pipe(es.split('\n'))
|
||||
|
||||
// keep only the lines that matched the term
|
||||
.pipe(filter())
|
||||
|
||||
// aggregate all matching lines and delegate control back to the file stream
|
||||
.pipe(aggregate())
|
||||
;
|
||||
});
|
||||
}
|
||||
|
||||
console.log('grepping for "arguments"');
|
||||
|
||||
// create a stream of all javascript files found in this and all sub directories
|
||||
readdirp({ root: path.join(__dirname), fileFilter: '*.js' })
|
||||
|
||||
// find all lines matching the term for each file (if none found, that file is ignored)
|
||||
.pipe(findLinesMatching('arguments'))
|
||||
|
||||
// format the results and output
|
||||
.pipe(
|
||||
es.mapSync(function (res) {
|
||||
return '\n\n' + res.file.path + '\n\t' + res.lines.join('\n\t');
|
||||
})
|
||||
)
|
||||
.pipe(process.stdout)
|
||||
;
|
||||
9
node_modules/readdirp/examples/package.json
generated
vendored
Normal file
9
node_modules/readdirp/examples/package.json
generated
vendored
Normal file
@@ -0,0 +1,9 @@
|
||||
{
|
||||
"name": "readdirp-examples",
|
||||
"version": "0.0.0",
|
||||
"description": "Examples for readdirp.",
|
||||
"dependencies": {
|
||||
"tap-stream": "~0.1.0",
|
||||
"event-stream": "~3.0.7"
|
||||
}
|
||||
}
|
||||
19
node_modules/readdirp/examples/stream-api-pipe.js
generated
vendored
Normal file
19
node_modules/readdirp/examples/stream-api-pipe.js
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
var readdirp = require('..')
|
||||
, path = require('path')
|
||||
, through = require('through2')
|
||||
|
||||
// print out all JavaScript files along with their size
|
||||
readdirp({ root: path.join(__dirname), fileFilter: '*.js' })
|
||||
.on('warn', function (err) { console.error('non-fatal error', err); })
|
||||
.on('error', function (err) { console.error('fatal error', err); })
|
||||
.pipe(through.obj(function (entry, _, cb) {
|
||||
this.push({ path: entry.path, size: entry.stat.size });
|
||||
cb();
|
||||
}))
|
||||
.pipe(through.obj(
|
||||
function (res, _, cb) {
|
||||
this.push(JSON.stringify(res) + '\n');
|
||||
cb();
|
||||
})
|
||||
)
|
||||
.pipe(process.stdout);
|
||||
15
node_modules/readdirp/examples/stream-api.js
generated
vendored
Normal file
15
node_modules/readdirp/examples/stream-api.js
generated
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
var readdirp = require('..')
|
||||
, path = require('path');
|
||||
|
||||
readdirp({ root: path.join(__dirname), fileFilter: '*.js' })
|
||||
.on('warn', function (err) {
|
||||
console.error('something went wrong when processing an entry', err);
|
||||
})
|
||||
.on('error', function (err) {
|
||||
console.error('something went fatally wrong and the stream was aborted', err);
|
||||
})
|
||||
.on('data', function (entry) {
|
||||
console.log('%s is ready for processing', entry.path);
|
||||
// process entry here
|
||||
});
|
||||
|
||||
15
node_modules/readdirp/node_modules/graceful-fs/LICENSE
generated
vendored
Normal file
15
node_modules/readdirp/node_modules/graceful-fs/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter, Ben Noordhuis, and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
133
node_modules/readdirp/node_modules/graceful-fs/README.md
generated
vendored
Normal file
133
node_modules/readdirp/node_modules/graceful-fs/README.md
generated
vendored
Normal file
@@ -0,0 +1,133 @@
|
||||
# graceful-fs
|
||||
|
||||
graceful-fs functions as a drop-in replacement for the fs module,
|
||||
making various improvements.
|
||||
|
||||
The improvements are meant to normalize behavior across different
|
||||
platforms and environments, and to make filesystem access more
|
||||
resilient to errors.
|
||||
|
||||
## Improvements over [fs module](https://nodejs.org/api/fs.html)
|
||||
|
||||
* Queues up `open` and `readdir` calls, and retries them once
|
||||
something closes if there is an EMFILE error from too many file
|
||||
descriptors.
|
||||
* fixes `lchmod` for Node versions prior to 0.6.2.
|
||||
* implements `fs.lutimes` if possible. Otherwise it becomes a noop.
|
||||
* ignores `EINVAL` and `EPERM` errors in `chown`, `fchown` or
|
||||
`lchown` if the user isn't root.
|
||||
* makes `lchmod` and `lchown` become noops, if not available.
|
||||
* retries reading a file if `read` results in EAGAIN error.
|
||||
|
||||
On Windows, it retries renaming a file for up to one second if `EACCESS`
|
||||
or `EPERM` error occurs, likely because antivirus software has locked
|
||||
the directory.
|
||||
|
||||
## USAGE
|
||||
|
||||
```javascript
|
||||
// use just like fs
|
||||
var fs = require('graceful-fs')
|
||||
|
||||
// now go and do stuff with it...
|
||||
fs.readFileSync('some-file-or-whatever')
|
||||
```
|
||||
|
||||
## Global Patching
|
||||
|
||||
If you want to patch the global fs module (or any other fs-like
|
||||
module) you can do this:
|
||||
|
||||
```javascript
|
||||
// Make sure to read the caveat below.
|
||||
var realFs = require('fs')
|
||||
var gracefulFs = require('graceful-fs')
|
||||
gracefulFs.gracefulify(realFs)
|
||||
```
|
||||
|
||||
This should only ever be done at the top-level application layer, in
|
||||
order to delay on EMFILE errors from any fs-using dependencies. You
|
||||
should **not** do this in a library, because it can cause unexpected
|
||||
delays in other parts of the program.
|
||||
|
||||
## Changes
|
||||
|
||||
This module is fairly stable at this point, and used by a lot of
|
||||
things. That being said, because it implements a subtle behavior
|
||||
change in a core part of the node API, even modest changes can be
|
||||
extremely breaking, and the versioning is thus biased towards
|
||||
bumping the major when in doubt.
|
||||
|
||||
The main change between major versions has been switching between
|
||||
providing a fully-patched `fs` module vs monkey-patching the node core
|
||||
builtin, and the approach by which a non-monkey-patched `fs` was
|
||||
created.
|
||||
|
||||
The goal is to trade `EMFILE` errors for slower fs operations. So, if
|
||||
you try to open a zillion files, rather than crashing, `open`
|
||||
operations will be queued up and wait for something else to `close`.
|
||||
|
||||
There are advantages to each approach. Monkey-patching the fs means
|
||||
that no `EMFILE` errors can possibly occur anywhere in your
|
||||
application, because everything is using the same core `fs` module,
|
||||
which is patched. However, it can also obviously cause undesirable
|
||||
side-effects, especially if the module is loaded multiple times.
|
||||
|
||||
Implementing a separate-but-identical patched `fs` module is more
|
||||
surgical (and doesn't run the risk of patching multiple times), but
|
||||
also imposes the challenge of keeping in sync with the core module.
|
||||
|
||||
The current approach loads the `fs` module, and then creates a
|
||||
lookalike object that has all the same methods, except a few that are
|
||||
patched. It is safe to use in all versions of Node from 0.8 through
|
||||
7.0.
|
||||
|
||||
### v4
|
||||
|
||||
* Do not monkey-patch the fs module. This module may now be used as a
|
||||
drop-in dep, and users can opt into monkey-patching the fs builtin
|
||||
if their app requires it.
|
||||
|
||||
### v3
|
||||
|
||||
* Monkey-patch fs, because the eval approach no longer works on recent
|
||||
node.
|
||||
* fixed possible type-error throw if rename fails on windows
|
||||
* verify that we *never* get EMFILE errors
|
||||
* Ignore ENOSYS from chmod/chown
|
||||
* clarify that graceful-fs must be used as a drop-in
|
||||
|
||||
### v2.1.0
|
||||
|
||||
* Use eval rather than monkey-patching fs.
|
||||
* readdir: Always sort the results
|
||||
* win32: requeue a file if error has an OK status
|
||||
|
||||
### v2.0
|
||||
|
||||
* A return to monkey patching
|
||||
* wrap process.cwd
|
||||
|
||||
### v1.1
|
||||
|
||||
* wrap readFile
|
||||
* Wrap fs.writeFile.
|
||||
* readdir protection
|
||||
* Don't clobber the fs builtin
|
||||
* Handle fs.read EAGAIN errors by trying again
|
||||
* Expose the curOpen counter
|
||||
* No-op lchown/lchmod if not implemented
|
||||
* fs.rename patch only for win32
|
||||
* Patch fs.rename to handle AV software on Windows
|
||||
* Close #4 Chown should not fail on einval or eperm if non-root
|
||||
* Fix isaacs/fstream#1 Only wrap fs one time
|
||||
* Fix #3 Start at 1024 max files, then back off on EMFILE
|
||||
* lutimes that doens't blow up on Linux
|
||||
* A full on-rewrite using a queue instead of just swallowing the EMFILE error
|
||||
* Wrap Read/Write streams as well
|
||||
|
||||
### 1.0
|
||||
|
||||
* Update engines for node 0.6
|
||||
* Be lstat-graceful on Windows
|
||||
* first
|
||||
21
node_modules/readdirp/node_modules/graceful-fs/fs.js
generated
vendored
Normal file
21
node_modules/readdirp/node_modules/graceful-fs/fs.js
generated
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
'use strict'
|
||||
|
||||
var fs = require('fs')
|
||||
|
||||
module.exports = clone(fs)
|
||||
|
||||
function clone (obj) {
|
||||
if (obj === null || typeof obj !== 'object')
|
||||
return obj
|
||||
|
||||
if (obj instanceof Object)
|
||||
var copy = { __proto__: obj.__proto__ }
|
||||
else
|
||||
var copy = Object.create(null)
|
||||
|
||||
Object.getOwnPropertyNames(obj).forEach(function (key) {
|
||||
Object.defineProperty(copy, key, Object.getOwnPropertyDescriptor(obj, key))
|
||||
})
|
||||
|
||||
return copy
|
||||
}
|
||||
262
node_modules/readdirp/node_modules/graceful-fs/graceful-fs.js
generated
vendored
Normal file
262
node_modules/readdirp/node_modules/graceful-fs/graceful-fs.js
generated
vendored
Normal file
@@ -0,0 +1,262 @@
|
||||
var fs = require('fs')
|
||||
var polyfills = require('./polyfills.js')
|
||||
var legacy = require('./legacy-streams.js')
|
||||
var queue = []
|
||||
|
||||
var util = require('util')
|
||||
|
||||
function noop () {}
|
||||
|
||||
var debug = noop
|
||||
if (util.debuglog)
|
||||
debug = util.debuglog('gfs4')
|
||||
else if (/\bgfs4\b/i.test(process.env.NODE_DEBUG || ''))
|
||||
debug = function() {
|
||||
var m = util.format.apply(util, arguments)
|
||||
m = 'GFS4: ' + m.split(/\n/).join('\nGFS4: ')
|
||||
console.error(m)
|
||||
}
|
||||
|
||||
if (/\bgfs4\b/i.test(process.env.NODE_DEBUG || '')) {
|
||||
process.on('exit', function() {
|
||||
debug(queue)
|
||||
require('assert').equal(queue.length, 0)
|
||||
})
|
||||
}
|
||||
|
||||
module.exports = patch(require('./fs.js'))
|
||||
if (process.env.TEST_GRACEFUL_FS_GLOBAL_PATCH) {
|
||||
module.exports = patch(fs)
|
||||
}
|
||||
|
||||
// Always patch fs.close/closeSync, because we want to
|
||||
// retry() whenever a close happens *anywhere* in the program.
|
||||
// This is essential when multiple graceful-fs instances are
|
||||
// in play at the same time.
|
||||
module.exports.close =
|
||||
fs.close = (function (fs$close) { return function (fd, cb) {
|
||||
return fs$close.call(fs, fd, function (err) {
|
||||
if (!err)
|
||||
retry()
|
||||
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
})
|
||||
}})(fs.close)
|
||||
|
||||
module.exports.closeSync =
|
||||
fs.closeSync = (function (fs$closeSync) { return function (fd) {
|
||||
// Note that graceful-fs also retries when fs.closeSync() fails.
|
||||
// Looks like a bug to me, although it's probably a harmless one.
|
||||
var rval = fs$closeSync.apply(fs, arguments)
|
||||
retry()
|
||||
return rval
|
||||
}})(fs.closeSync)
|
||||
|
||||
function patch (fs) {
|
||||
// Everything that references the open() function needs to be in here
|
||||
polyfills(fs)
|
||||
fs.gracefulify = patch
|
||||
fs.FileReadStream = ReadStream; // Legacy name.
|
||||
fs.FileWriteStream = WriteStream; // Legacy name.
|
||||
fs.createReadStream = createReadStream
|
||||
fs.createWriteStream = createWriteStream
|
||||
var fs$readFile = fs.readFile
|
||||
fs.readFile = readFile
|
||||
function readFile (path, options, cb) {
|
||||
if (typeof options === 'function')
|
||||
cb = options, options = null
|
||||
|
||||
return go$readFile(path, options, cb)
|
||||
|
||||
function go$readFile (path, options, cb) {
|
||||
return fs$readFile(path, options, function (err) {
|
||||
if (err && (err.code === 'EMFILE' || err.code === 'ENFILE'))
|
||||
enqueue([go$readFile, [path, options, cb]])
|
||||
else {
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
retry()
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
var fs$writeFile = fs.writeFile
|
||||
fs.writeFile = writeFile
|
||||
function writeFile (path, data, options, cb) {
|
||||
if (typeof options === 'function')
|
||||
cb = options, options = null
|
||||
|
||||
return go$writeFile(path, data, options, cb)
|
||||
|
||||
function go$writeFile (path, data, options, cb) {
|
||||
return fs$writeFile(path, data, options, function (err) {
|
||||
if (err && (err.code === 'EMFILE' || err.code === 'ENFILE'))
|
||||
enqueue([go$writeFile, [path, data, options, cb]])
|
||||
else {
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
retry()
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
var fs$appendFile = fs.appendFile
|
||||
if (fs$appendFile)
|
||||
fs.appendFile = appendFile
|
||||
function appendFile (path, data, options, cb) {
|
||||
if (typeof options === 'function')
|
||||
cb = options, options = null
|
||||
|
||||
return go$appendFile(path, data, options, cb)
|
||||
|
||||
function go$appendFile (path, data, options, cb) {
|
||||
return fs$appendFile(path, data, options, function (err) {
|
||||
if (err && (err.code === 'EMFILE' || err.code === 'ENFILE'))
|
||||
enqueue([go$appendFile, [path, data, options, cb]])
|
||||
else {
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
retry()
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
var fs$readdir = fs.readdir
|
||||
fs.readdir = readdir
|
||||
function readdir (path, options, cb) {
|
||||
var args = [path]
|
||||
if (typeof options !== 'function') {
|
||||
args.push(options)
|
||||
} else {
|
||||
cb = options
|
||||
}
|
||||
args.push(go$readdir$cb)
|
||||
|
||||
return go$readdir(args)
|
||||
|
||||
function go$readdir$cb (err, files) {
|
||||
if (files && files.sort)
|
||||
files.sort()
|
||||
|
||||
if (err && (err.code === 'EMFILE' || err.code === 'ENFILE'))
|
||||
enqueue([go$readdir, [args]])
|
||||
else {
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
retry()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function go$readdir (args) {
|
||||
return fs$readdir.apply(fs, args)
|
||||
}
|
||||
|
||||
if (process.version.substr(0, 4) === 'v0.8') {
|
||||
var legStreams = legacy(fs)
|
||||
ReadStream = legStreams.ReadStream
|
||||
WriteStream = legStreams.WriteStream
|
||||
}
|
||||
|
||||
var fs$ReadStream = fs.ReadStream
|
||||
ReadStream.prototype = Object.create(fs$ReadStream.prototype)
|
||||
ReadStream.prototype.open = ReadStream$open
|
||||
|
||||
var fs$WriteStream = fs.WriteStream
|
||||
WriteStream.prototype = Object.create(fs$WriteStream.prototype)
|
||||
WriteStream.prototype.open = WriteStream$open
|
||||
|
||||
fs.ReadStream = ReadStream
|
||||
fs.WriteStream = WriteStream
|
||||
|
||||
function ReadStream (path, options) {
|
||||
if (this instanceof ReadStream)
|
||||
return fs$ReadStream.apply(this, arguments), this
|
||||
else
|
||||
return ReadStream.apply(Object.create(ReadStream.prototype), arguments)
|
||||
}
|
||||
|
||||
function ReadStream$open () {
|
||||
var that = this
|
||||
open(that.path, that.flags, that.mode, function (err, fd) {
|
||||
if (err) {
|
||||
if (that.autoClose)
|
||||
that.destroy()
|
||||
|
||||
that.emit('error', err)
|
||||
} else {
|
||||
that.fd = fd
|
||||
that.emit('open', fd)
|
||||
that.read()
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
function WriteStream (path, options) {
|
||||
if (this instanceof WriteStream)
|
||||
return fs$WriteStream.apply(this, arguments), this
|
||||
else
|
||||
return WriteStream.apply(Object.create(WriteStream.prototype), arguments)
|
||||
}
|
||||
|
||||
function WriteStream$open () {
|
||||
var that = this
|
||||
open(that.path, that.flags, that.mode, function (err, fd) {
|
||||
if (err) {
|
||||
that.destroy()
|
||||
that.emit('error', err)
|
||||
} else {
|
||||
that.fd = fd
|
||||
that.emit('open', fd)
|
||||
}
|
||||
})
|
||||
}
|
||||
|
||||
function createReadStream (path, options) {
|
||||
return new ReadStream(path, options)
|
||||
}
|
||||
|
||||
function createWriteStream (path, options) {
|
||||
return new WriteStream(path, options)
|
||||
}
|
||||
|
||||
var fs$open = fs.open
|
||||
fs.open = open
|
||||
function open (path, flags, mode, cb) {
|
||||
if (typeof mode === 'function')
|
||||
cb = mode, mode = null
|
||||
|
||||
return go$open(path, flags, mode, cb)
|
||||
|
||||
function go$open (path, flags, mode, cb) {
|
||||
return fs$open(path, flags, mode, function (err, fd) {
|
||||
if (err && (err.code === 'EMFILE' || err.code === 'ENFILE'))
|
||||
enqueue([go$open, [path, flags, mode, cb]])
|
||||
else {
|
||||
if (typeof cb === 'function')
|
||||
cb.apply(this, arguments)
|
||||
retry()
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
return fs
|
||||
}
|
||||
|
||||
function enqueue (elem) {
|
||||
debug('ENQUEUE', elem[0].name, elem[1])
|
||||
queue.push(elem)
|
||||
}
|
||||
|
||||
function retry () {
|
||||
var elem = queue.shift()
|
||||
if (elem) {
|
||||
debug('RETRY', elem[0].name, elem[1])
|
||||
elem[0].apply(null, elem[1])
|
||||
}
|
||||
}
|
||||
118
node_modules/readdirp/node_modules/graceful-fs/legacy-streams.js
generated
vendored
Normal file
118
node_modules/readdirp/node_modules/graceful-fs/legacy-streams.js
generated
vendored
Normal file
@@ -0,0 +1,118 @@
|
||||
var Stream = require('stream').Stream
|
||||
|
||||
module.exports = legacy
|
||||
|
||||
function legacy (fs) {
|
||||
return {
|
||||
ReadStream: ReadStream,
|
||||
WriteStream: WriteStream
|
||||
}
|
||||
|
||||
function ReadStream (path, options) {
|
||||
if (!(this instanceof ReadStream)) return new ReadStream(path, options);
|
||||
|
||||
Stream.call(this);
|
||||
|
||||
var self = this;
|
||||
|
||||
this.path = path;
|
||||
this.fd = null;
|
||||
this.readable = true;
|
||||
this.paused = false;
|
||||
|
||||
this.flags = 'r';
|
||||
this.mode = 438; /*=0666*/
|
||||
this.bufferSize = 64 * 1024;
|
||||
|
||||
options = options || {};
|
||||
|
||||
// Mixin options into this
|
||||
var keys = Object.keys(options);
|
||||
for (var index = 0, length = keys.length; index < length; index++) {
|
||||
var key = keys[index];
|
||||
this[key] = options[key];
|
||||
}
|
||||
|
||||
if (this.encoding) this.setEncoding(this.encoding);
|
||||
|
||||
if (this.start !== undefined) {
|
||||
if ('number' !== typeof this.start) {
|
||||
throw TypeError('start must be a Number');
|
||||
}
|
||||
if (this.end === undefined) {
|
||||
this.end = Infinity;
|
||||
} else if ('number' !== typeof this.end) {
|
||||
throw TypeError('end must be a Number');
|
||||
}
|
||||
|
||||
if (this.start > this.end) {
|
||||
throw new Error('start must be <= end');
|
||||
}
|
||||
|
||||
this.pos = this.start;
|
||||
}
|
||||
|
||||
if (this.fd !== null) {
|
||||
process.nextTick(function() {
|
||||
self._read();
|
||||
});
|
||||
return;
|
||||
}
|
||||
|
||||
fs.open(this.path, this.flags, this.mode, function (err, fd) {
|
||||
if (err) {
|
||||
self.emit('error', err);
|
||||
self.readable = false;
|
||||
return;
|
||||
}
|
||||
|
||||
self.fd = fd;
|
||||
self.emit('open', fd);
|
||||
self._read();
|
||||
})
|
||||
}
|
||||
|
||||
function WriteStream (path, options) {
|
||||
if (!(this instanceof WriteStream)) return new WriteStream(path, options);
|
||||
|
||||
Stream.call(this);
|
||||
|
||||
this.path = path;
|
||||
this.fd = null;
|
||||
this.writable = true;
|
||||
|
||||
this.flags = 'w';
|
||||
this.encoding = 'binary';
|
||||
this.mode = 438; /*=0666*/
|
||||
this.bytesWritten = 0;
|
||||
|
||||
options = options || {};
|
||||
|
||||
// Mixin options into this
|
||||
var keys = Object.keys(options);
|
||||
for (var index = 0, length = keys.length; index < length; index++) {
|
||||
var key = keys[index];
|
||||
this[key] = options[key];
|
||||
}
|
||||
|
||||
if (this.start !== undefined) {
|
||||
if ('number' !== typeof this.start) {
|
||||
throw TypeError('start must be a Number');
|
||||
}
|
||||
if (this.start < 0) {
|
||||
throw new Error('start must be >= zero');
|
||||
}
|
||||
|
||||
this.pos = this.start;
|
||||
}
|
||||
|
||||
this.busy = false;
|
||||
this._queue = [];
|
||||
|
||||
if (this.fd === null) {
|
||||
this._open = fs.open;
|
||||
this._queue.push([this._open, this.path, this.flags, this.mode, undefined]);
|
||||
this.flush();
|
||||
}
|
||||
}
|
||||
}
|
||||
111
node_modules/readdirp/node_modules/graceful-fs/package.json
generated
vendored
Normal file
111
node_modules/readdirp/node_modules/graceful-fs/package.json
generated
vendored
Normal file
@@ -0,0 +1,111 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "graceful-fs@^4.1.2",
|
||||
"scope": null,
|
||||
"escapedName": "graceful-fs",
|
||||
"name": "graceful-fs",
|
||||
"rawSpec": "^4.1.2",
|
||||
"spec": ">=4.1.2 <5.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp"
|
||||
]
|
||||
],
|
||||
"_from": "graceful-fs@>=4.1.2 <5.0.0",
|
||||
"_id": "graceful-fs@4.1.11",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp/graceful-fs",
|
||||
"_nodeVersion": "6.5.0",
|
||||
"_npmOperationalInternal": {
|
||||
"host": "packages-18-east.internal.npmjs.com",
|
||||
"tmp": "tmp/graceful-fs-4.1.11.tgz_1479843029430_0.2122855328489095"
|
||||
},
|
||||
"_npmUser": {
|
||||
"name": "isaacs",
|
||||
"email": "i@izs.me"
|
||||
},
|
||||
"_npmVersion": "3.10.9",
|
||||
"_phantomChildren": {},
|
||||
"_requested": {
|
||||
"raw": "graceful-fs@^4.1.2",
|
||||
"scope": null,
|
||||
"escapedName": "graceful-fs",
|
||||
"name": "graceful-fs",
|
||||
"rawSpec": "^4.1.2",
|
||||
"spec": ">=4.1.2 <5.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/readdirp"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/graceful-fs/-/graceful-fs-4.1.11.tgz",
|
||||
"_shasum": "0e8bdfe4d1ddb8854d64e04ea7c00e2a026e5658",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "graceful-fs@^4.1.2",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp",
|
||||
"bugs": {
|
||||
"url": "https://github.com/isaacs/node-graceful-fs/issues"
|
||||
},
|
||||
"dependencies": {},
|
||||
"description": "A drop-in replacement for fs, making various improvements.",
|
||||
"devDependencies": {
|
||||
"mkdirp": "^0.5.0",
|
||||
"rimraf": "^2.2.8",
|
||||
"tap": "^5.4.2"
|
||||
},
|
||||
"directories": {
|
||||
"test": "test"
|
||||
},
|
||||
"dist": {
|
||||
"shasum": "0e8bdfe4d1ddb8854d64e04ea7c00e2a026e5658",
|
||||
"tarball": "https://registry.npmjs.org/graceful-fs/-/graceful-fs-4.1.11.tgz"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=0.4.0"
|
||||
},
|
||||
"files": [
|
||||
"fs.js",
|
||||
"graceful-fs.js",
|
||||
"legacy-streams.js",
|
||||
"polyfills.js"
|
||||
],
|
||||
"gitHead": "65cf80d1fd3413b823c16c626c1e7c326452bee5",
|
||||
"homepage": "https://github.com/isaacs/node-graceful-fs#readme",
|
||||
"keywords": [
|
||||
"fs",
|
||||
"module",
|
||||
"reading",
|
||||
"retry",
|
||||
"retries",
|
||||
"queue",
|
||||
"error",
|
||||
"errors",
|
||||
"handling",
|
||||
"EMFILE",
|
||||
"EAGAIN",
|
||||
"EINVAL",
|
||||
"EPERM",
|
||||
"EACCESS"
|
||||
],
|
||||
"license": "ISC",
|
||||
"main": "graceful-fs.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "isaacs",
|
||||
"email": "i@izs.me"
|
||||
}
|
||||
],
|
||||
"name": "graceful-fs",
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git+https://github.com/isaacs/node-graceful-fs.git"
|
||||
},
|
||||
"scripts": {
|
||||
"test": "node test.js | tap -"
|
||||
},
|
||||
"version": "4.1.11"
|
||||
}
|
||||
330
node_modules/readdirp/node_modules/graceful-fs/polyfills.js
generated
vendored
Normal file
330
node_modules/readdirp/node_modules/graceful-fs/polyfills.js
generated
vendored
Normal file
@@ -0,0 +1,330 @@
|
||||
var fs = require('./fs.js')
|
||||
var constants = require('constants')
|
||||
|
||||
var origCwd = process.cwd
|
||||
var cwd = null
|
||||
|
||||
var platform = process.env.GRACEFUL_FS_PLATFORM || process.platform
|
||||
|
||||
process.cwd = function() {
|
||||
if (!cwd)
|
||||
cwd = origCwd.call(process)
|
||||
return cwd
|
||||
}
|
||||
try {
|
||||
process.cwd()
|
||||
} catch (er) {}
|
||||
|
||||
var chdir = process.chdir
|
||||
process.chdir = function(d) {
|
||||
cwd = null
|
||||
chdir.call(process, d)
|
||||
}
|
||||
|
||||
module.exports = patch
|
||||
|
||||
function patch (fs) {
|
||||
// (re-)implement some things that are known busted or missing.
|
||||
|
||||
// lchmod, broken prior to 0.6.2
|
||||
// back-port the fix here.
|
||||
if (constants.hasOwnProperty('O_SYMLINK') &&
|
||||
process.version.match(/^v0\.6\.[0-2]|^v0\.5\./)) {
|
||||
patchLchmod(fs)
|
||||
}
|
||||
|
||||
// lutimes implementation, or no-op
|
||||
if (!fs.lutimes) {
|
||||
patchLutimes(fs)
|
||||
}
|
||||
|
||||
// https://github.com/isaacs/node-graceful-fs/issues/4
|
||||
// Chown should not fail on einval or eperm if non-root.
|
||||
// It should not fail on enosys ever, as this just indicates
|
||||
// that a fs doesn't support the intended operation.
|
||||
|
||||
fs.chown = chownFix(fs.chown)
|
||||
fs.fchown = chownFix(fs.fchown)
|
||||
fs.lchown = chownFix(fs.lchown)
|
||||
|
||||
fs.chmod = chmodFix(fs.chmod)
|
||||
fs.fchmod = chmodFix(fs.fchmod)
|
||||
fs.lchmod = chmodFix(fs.lchmod)
|
||||
|
||||
fs.chownSync = chownFixSync(fs.chownSync)
|
||||
fs.fchownSync = chownFixSync(fs.fchownSync)
|
||||
fs.lchownSync = chownFixSync(fs.lchownSync)
|
||||
|
||||
fs.chmodSync = chmodFixSync(fs.chmodSync)
|
||||
fs.fchmodSync = chmodFixSync(fs.fchmodSync)
|
||||
fs.lchmodSync = chmodFixSync(fs.lchmodSync)
|
||||
|
||||
fs.stat = statFix(fs.stat)
|
||||
fs.fstat = statFix(fs.fstat)
|
||||
fs.lstat = statFix(fs.lstat)
|
||||
|
||||
fs.statSync = statFixSync(fs.statSync)
|
||||
fs.fstatSync = statFixSync(fs.fstatSync)
|
||||
fs.lstatSync = statFixSync(fs.lstatSync)
|
||||
|
||||
// if lchmod/lchown do not exist, then make them no-ops
|
||||
if (!fs.lchmod) {
|
||||
fs.lchmod = function (path, mode, cb) {
|
||||
if (cb) process.nextTick(cb)
|
||||
}
|
||||
fs.lchmodSync = function () {}
|
||||
}
|
||||
if (!fs.lchown) {
|
||||
fs.lchown = function (path, uid, gid, cb) {
|
||||
if (cb) process.nextTick(cb)
|
||||
}
|
||||
fs.lchownSync = function () {}
|
||||
}
|
||||
|
||||
// on Windows, A/V software can lock the directory, causing this
|
||||
// to fail with an EACCES or EPERM if the directory contains newly
|
||||
// created files. Try again on failure, for up to 60 seconds.
|
||||
|
||||
// Set the timeout this long because some Windows Anti-Virus, such as Parity
|
||||
// bit9, may lock files for up to a minute, causing npm package install
|
||||
// failures. Also, take care to yield the scheduler. Windows scheduling gives
|
||||
// CPU to a busy looping process, which can cause the program causing the lock
|
||||
// contention to be starved of CPU by node, so the contention doesn't resolve.
|
||||
if (platform === "win32") {
|
||||
fs.rename = (function (fs$rename) { return function (from, to, cb) {
|
||||
var start = Date.now()
|
||||
var backoff = 0;
|
||||
fs$rename(from, to, function CB (er) {
|
||||
if (er
|
||||
&& (er.code === "EACCES" || er.code === "EPERM")
|
||||
&& Date.now() - start < 60000) {
|
||||
setTimeout(function() {
|
||||
fs.stat(to, function (stater, st) {
|
||||
if (stater && stater.code === "ENOENT")
|
||||
fs$rename(from, to, CB);
|
||||
else
|
||||
cb(er)
|
||||
})
|
||||
}, backoff)
|
||||
if (backoff < 100)
|
||||
backoff += 10;
|
||||
return;
|
||||
}
|
||||
if (cb) cb(er)
|
||||
})
|
||||
}})(fs.rename)
|
||||
}
|
||||
|
||||
// if read() returns EAGAIN, then just try it again.
|
||||
fs.read = (function (fs$read) { return function (fd, buffer, offset, length, position, callback_) {
|
||||
var callback
|
||||
if (callback_ && typeof callback_ === 'function') {
|
||||
var eagCounter = 0
|
||||
callback = function (er, _, __) {
|
||||
if (er && er.code === 'EAGAIN' && eagCounter < 10) {
|
||||
eagCounter ++
|
||||
return fs$read.call(fs, fd, buffer, offset, length, position, callback)
|
||||
}
|
||||
callback_.apply(this, arguments)
|
||||
}
|
||||
}
|
||||
return fs$read.call(fs, fd, buffer, offset, length, position, callback)
|
||||
}})(fs.read)
|
||||
|
||||
fs.readSync = (function (fs$readSync) { return function (fd, buffer, offset, length, position) {
|
||||
var eagCounter = 0
|
||||
while (true) {
|
||||
try {
|
||||
return fs$readSync.call(fs, fd, buffer, offset, length, position)
|
||||
} catch (er) {
|
||||
if (er.code === 'EAGAIN' && eagCounter < 10) {
|
||||
eagCounter ++
|
||||
continue
|
||||
}
|
||||
throw er
|
||||
}
|
||||
}
|
||||
}})(fs.readSync)
|
||||
}
|
||||
|
||||
function patchLchmod (fs) {
|
||||
fs.lchmod = function (path, mode, callback) {
|
||||
fs.open( path
|
||||
, constants.O_WRONLY | constants.O_SYMLINK
|
||||
, mode
|
||||
, function (err, fd) {
|
||||
if (err) {
|
||||
if (callback) callback(err)
|
||||
return
|
||||
}
|
||||
// prefer to return the chmod error, if one occurs,
|
||||
// but still try to close, and report closing errors if they occur.
|
||||
fs.fchmod(fd, mode, function (err) {
|
||||
fs.close(fd, function(err2) {
|
||||
if (callback) callback(err || err2)
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
fs.lchmodSync = function (path, mode) {
|
||||
var fd = fs.openSync(path, constants.O_WRONLY | constants.O_SYMLINK, mode)
|
||||
|
||||
// prefer to return the chmod error, if one occurs,
|
||||
// but still try to close, and report closing errors if they occur.
|
||||
var threw = true
|
||||
var ret
|
||||
try {
|
||||
ret = fs.fchmodSync(fd, mode)
|
||||
threw = false
|
||||
} finally {
|
||||
if (threw) {
|
||||
try {
|
||||
fs.closeSync(fd)
|
||||
} catch (er) {}
|
||||
} else {
|
||||
fs.closeSync(fd)
|
||||
}
|
||||
}
|
||||
return ret
|
||||
}
|
||||
}
|
||||
|
||||
function patchLutimes (fs) {
|
||||
if (constants.hasOwnProperty("O_SYMLINK")) {
|
||||
fs.lutimes = function (path, at, mt, cb) {
|
||||
fs.open(path, constants.O_SYMLINK, function (er, fd) {
|
||||
if (er) {
|
||||
if (cb) cb(er)
|
||||
return
|
||||
}
|
||||
fs.futimes(fd, at, mt, function (er) {
|
||||
fs.close(fd, function (er2) {
|
||||
if (cb) cb(er || er2)
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
fs.lutimesSync = function (path, at, mt) {
|
||||
var fd = fs.openSync(path, constants.O_SYMLINK)
|
||||
var ret
|
||||
var threw = true
|
||||
try {
|
||||
ret = fs.futimesSync(fd, at, mt)
|
||||
threw = false
|
||||
} finally {
|
||||
if (threw) {
|
||||
try {
|
||||
fs.closeSync(fd)
|
||||
} catch (er) {}
|
||||
} else {
|
||||
fs.closeSync(fd)
|
||||
}
|
||||
}
|
||||
return ret
|
||||
}
|
||||
|
||||
} else {
|
||||
fs.lutimes = function (_a, _b, _c, cb) { if (cb) process.nextTick(cb) }
|
||||
fs.lutimesSync = function () {}
|
||||
}
|
||||
}
|
||||
|
||||
function chmodFix (orig) {
|
||||
if (!orig) return orig
|
||||
return function (target, mode, cb) {
|
||||
return orig.call(fs, target, mode, function (er) {
|
||||
if (chownErOk(er)) er = null
|
||||
if (cb) cb.apply(this, arguments)
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
function chmodFixSync (orig) {
|
||||
if (!orig) return orig
|
||||
return function (target, mode) {
|
||||
try {
|
||||
return orig.call(fs, target, mode)
|
||||
} catch (er) {
|
||||
if (!chownErOk(er)) throw er
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
function chownFix (orig) {
|
||||
if (!orig) return orig
|
||||
return function (target, uid, gid, cb) {
|
||||
return orig.call(fs, target, uid, gid, function (er) {
|
||||
if (chownErOk(er)) er = null
|
||||
if (cb) cb.apply(this, arguments)
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
function chownFixSync (orig) {
|
||||
if (!orig) return orig
|
||||
return function (target, uid, gid) {
|
||||
try {
|
||||
return orig.call(fs, target, uid, gid)
|
||||
} catch (er) {
|
||||
if (!chownErOk(er)) throw er
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
function statFix (orig) {
|
||||
if (!orig) return orig
|
||||
// Older versions of Node erroneously returned signed integers for
|
||||
// uid + gid.
|
||||
return function (target, cb) {
|
||||
return orig.call(fs, target, function (er, stats) {
|
||||
if (!stats) return cb.apply(this, arguments)
|
||||
if (stats.uid < 0) stats.uid += 0x100000000
|
||||
if (stats.gid < 0) stats.gid += 0x100000000
|
||||
if (cb) cb.apply(this, arguments)
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
function statFixSync (orig) {
|
||||
if (!orig) return orig
|
||||
// Older versions of Node erroneously returned signed integers for
|
||||
// uid + gid.
|
||||
return function (target) {
|
||||
var stats = orig.call(fs, target)
|
||||
if (stats.uid < 0) stats.uid += 0x100000000
|
||||
if (stats.gid < 0) stats.gid += 0x100000000
|
||||
return stats;
|
||||
}
|
||||
}
|
||||
|
||||
// ENOSYS means that the fs doesn't support the op. Just ignore
|
||||
// that, because it doesn't matter.
|
||||
//
|
||||
// if there's no getuid, or if getuid() is something other
|
||||
// than 0, and the error is EINVAL or EPERM, then just ignore
|
||||
// it.
|
||||
//
|
||||
// This specific case is a silent failure in cp, install, tar,
|
||||
// and most other unix tools that manage permissions.
|
||||
//
|
||||
// When running as root, or if other types of errors are
|
||||
// encountered, then it's strict.
|
||||
function chownErOk (er) {
|
||||
if (!er)
|
||||
return true
|
||||
|
||||
if (er.code === "ENOSYS")
|
||||
return true
|
||||
|
||||
var nonroot = !process.getuid || process.getuid() !== 0
|
||||
if (nonroot) {
|
||||
if (er.code === "EINVAL" || er.code === "EPERM")
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
1
node_modules/readdirp/node_modules/isarray/.npmignore
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/isarray/.npmignore
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
node_modules
|
||||
4
node_modules/readdirp/node_modules/isarray/.travis.yml
generated
vendored
Normal file
4
node_modules/readdirp/node_modules/isarray/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,4 @@
|
||||
language: node_js
|
||||
node_js:
|
||||
- "0.8"
|
||||
- "0.10"
|
||||
6
node_modules/readdirp/node_modules/isarray/Makefile
generated
vendored
Normal file
6
node_modules/readdirp/node_modules/isarray/Makefile
generated
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
|
||||
test:
|
||||
@node_modules/.bin/tape test.js
|
||||
|
||||
.PHONY: test
|
||||
|
||||
60
node_modules/readdirp/node_modules/isarray/README.md
generated
vendored
Normal file
60
node_modules/readdirp/node_modules/isarray/README.md
generated
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
|
||||
# isarray
|
||||
|
||||
`Array#isArray` for older browsers.
|
||||
|
||||
[](http://travis-ci.org/juliangruber/isarray)
|
||||
[](https://www.npmjs.org/package/isarray)
|
||||
|
||||
[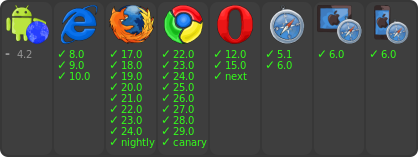
|
||||
](https://ci.testling.com/juliangruber/isarray)
|
||||
|
||||
## Usage
|
||||
|
||||
```js
|
||||
var isArray = require('isarray');
|
||||
|
||||
console.log(isArray([])); // => true
|
||||
console.log(isArray({})); // => false
|
||||
```
|
||||
|
||||
## Installation
|
||||
|
||||
With [npm](http://npmjs.org) do
|
||||
|
||||
```bash
|
||||
$ npm install isarray
|
||||
```
|
||||
|
||||
Then bundle for the browser with
|
||||
[browserify](https://github.com/substack/browserify).
|
||||
|
||||
With [component](http://component.io) do
|
||||
|
||||
```bash
|
||||
$ component install juliangruber/isarray
|
||||
```
|
||||
|
||||
## License
|
||||
|
||||
(MIT)
|
||||
|
||||
Copyright (c) 2013 Julian Gruber <julian@juliangruber.com>
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of
|
||||
this software and associated documentation files (the "Software"), to deal in
|
||||
the Software without restriction, including without limitation the rights to
|
||||
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies
|
||||
of the Software, and to permit persons to whom the Software is furnished to do
|
||||
so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
19
node_modules/readdirp/node_modules/isarray/component.json
generated
vendored
Normal file
19
node_modules/readdirp/node_modules/isarray/component.json
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
{
|
||||
"name" : "isarray",
|
||||
"description" : "Array#isArray for older browsers",
|
||||
"version" : "0.0.1",
|
||||
"repository" : "juliangruber/isarray",
|
||||
"homepage": "https://github.com/juliangruber/isarray",
|
||||
"main" : "index.js",
|
||||
"scripts" : [
|
||||
"index.js"
|
||||
],
|
||||
"dependencies" : {},
|
||||
"keywords": ["browser","isarray","array"],
|
||||
"author": {
|
||||
"name": "Julian Gruber",
|
||||
"email": "mail@juliangruber.com",
|
||||
"url": "http://juliangruber.com"
|
||||
},
|
||||
"license": "MIT"
|
||||
}
|
||||
5
node_modules/readdirp/node_modules/isarray/index.js
generated
vendored
Normal file
5
node_modules/readdirp/node_modules/isarray/index.js
generated
vendored
Normal file
@@ -0,0 +1,5 @@
|
||||
var toString = {}.toString;
|
||||
|
||||
module.exports = Array.isArray || function (arr) {
|
||||
return toString.call(arr) == '[object Array]';
|
||||
};
|
||||
104
node_modules/readdirp/node_modules/isarray/package.json
generated
vendored
Normal file
104
node_modules/readdirp/node_modules/isarray/package.json
generated
vendored
Normal file
@@ -0,0 +1,104 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "isarray@~1.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "isarray",
|
||||
"name": "isarray",
|
||||
"rawSpec": "~1.0.0",
|
||||
"spec": ">=1.0.0 <1.1.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp\\node_modules\\readable-stream"
|
||||
]
|
||||
],
|
||||
"_from": "isarray@>=1.0.0 <1.1.0",
|
||||
"_id": "isarray@1.0.0",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp/isarray",
|
||||
"_nodeVersion": "5.1.0",
|
||||
"_npmUser": {
|
||||
"name": "juliangruber",
|
||||
"email": "julian@juliangruber.com"
|
||||
},
|
||||
"_npmVersion": "3.3.12",
|
||||
"_phantomChildren": {},
|
||||
"_requested": {
|
||||
"raw": "isarray@~1.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "isarray",
|
||||
"name": "isarray",
|
||||
"rawSpec": "~1.0.0",
|
||||
"spec": ">=1.0.0 <1.1.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/readdirp/readable-stream"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/isarray/-/isarray-1.0.0.tgz",
|
||||
"_shasum": "bb935d48582cba168c06834957a54a3e07124f11",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "isarray@~1.0.0",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp\\node_modules\\readable-stream",
|
||||
"author": {
|
||||
"name": "Julian Gruber",
|
||||
"email": "mail@juliangruber.com",
|
||||
"url": "http://juliangruber.com"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/juliangruber/isarray/issues"
|
||||
},
|
||||
"dependencies": {},
|
||||
"description": "Array#isArray for older browsers",
|
||||
"devDependencies": {
|
||||
"tape": "~2.13.4"
|
||||
},
|
||||
"directories": {},
|
||||
"dist": {
|
||||
"shasum": "bb935d48582cba168c06834957a54a3e07124f11",
|
||||
"tarball": "https://registry.npmjs.org/isarray/-/isarray-1.0.0.tgz"
|
||||
},
|
||||
"gitHead": "2a23a281f369e9ae06394c0fb4d2381355a6ba33",
|
||||
"homepage": "https://github.com/juliangruber/isarray",
|
||||
"keywords": [
|
||||
"browser",
|
||||
"isarray",
|
||||
"array"
|
||||
],
|
||||
"license": "MIT",
|
||||
"main": "index.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "juliangruber",
|
||||
"email": "julian@juliangruber.com"
|
||||
}
|
||||
],
|
||||
"name": "isarray",
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/juliangruber/isarray.git"
|
||||
},
|
||||
"scripts": {
|
||||
"test": "tape test.js"
|
||||
},
|
||||
"testling": {
|
||||
"files": "test.js",
|
||||
"browsers": [
|
||||
"ie/8..latest",
|
||||
"firefox/17..latest",
|
||||
"firefox/nightly",
|
||||
"chrome/22..latest",
|
||||
"chrome/canary",
|
||||
"opera/12..latest",
|
||||
"opera/next",
|
||||
"safari/5.1..latest",
|
||||
"ipad/6.0..latest",
|
||||
"iphone/6.0..latest",
|
||||
"android-browser/4.2..latest"
|
||||
]
|
||||
},
|
||||
"version": "1.0.0"
|
||||
}
|
||||
20
node_modules/readdirp/node_modules/isarray/test.js
generated
vendored
Normal file
20
node_modules/readdirp/node_modules/isarray/test.js
generated
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
var isArray = require('./');
|
||||
var test = require('tape');
|
||||
|
||||
test('is array', function(t){
|
||||
t.ok(isArray([]));
|
||||
t.notOk(isArray({}));
|
||||
t.notOk(isArray(null));
|
||||
t.notOk(isArray(false));
|
||||
|
||||
var obj = {};
|
||||
obj[0] = true;
|
||||
t.notOk(isArray(obj));
|
||||
|
||||
var arr = [];
|
||||
arr.foo = 'bar';
|
||||
t.ok(isArray(arr));
|
||||
|
||||
t.end();
|
||||
});
|
||||
|
||||
15
node_modules/readdirp/node_modules/minimatch/LICENSE
generated
vendored
Normal file
15
node_modules/readdirp/node_modules/minimatch/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
The ISC License
|
||||
|
||||
Copyright (c) Isaac Z. Schlueter and Contributors
|
||||
|
||||
Permission to use, copy, modify, and/or distribute this software for any
|
||||
purpose with or without fee is hereby granted, provided that the above
|
||||
copyright notice and this permission notice appear in all copies.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
||||
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
||||
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
||||
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
||||
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
||||
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR
|
||||
IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
||||
209
node_modules/readdirp/node_modules/minimatch/README.md
generated
vendored
Normal file
209
node_modules/readdirp/node_modules/minimatch/README.md
generated
vendored
Normal file
@@ -0,0 +1,209 @@
|
||||
# minimatch
|
||||
|
||||
A minimal matching utility.
|
||||
|
||||
[](http://travis-ci.org/isaacs/minimatch)
|
||||
|
||||
|
||||
This is the matching library used internally by npm.
|
||||
|
||||
It works by converting glob expressions into JavaScript `RegExp`
|
||||
objects.
|
||||
|
||||
## Usage
|
||||
|
||||
```javascript
|
||||
var minimatch = require("minimatch")
|
||||
|
||||
minimatch("bar.foo", "*.foo") // true!
|
||||
minimatch("bar.foo", "*.bar") // false!
|
||||
minimatch("bar.foo", "*.+(bar|foo)", { debug: true }) // true, and noisy!
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
Supports these glob features:
|
||||
|
||||
* Brace Expansion
|
||||
* Extended glob matching
|
||||
* "Globstar" `**` matching
|
||||
|
||||
See:
|
||||
|
||||
* `man sh`
|
||||
* `man bash`
|
||||
* `man 3 fnmatch`
|
||||
* `man 5 gitignore`
|
||||
|
||||
## Minimatch Class
|
||||
|
||||
Create a minimatch object by instantiating the `minimatch.Minimatch` class.
|
||||
|
||||
```javascript
|
||||
var Minimatch = require("minimatch").Minimatch
|
||||
var mm = new Minimatch(pattern, options)
|
||||
```
|
||||
|
||||
### Properties
|
||||
|
||||
* `pattern` The original pattern the minimatch object represents.
|
||||
* `options` The options supplied to the constructor.
|
||||
* `set` A 2-dimensional array of regexp or string expressions.
|
||||
Each row in the
|
||||
array corresponds to a brace-expanded pattern. Each item in the row
|
||||
corresponds to a single path-part. For example, the pattern
|
||||
`{a,b/c}/d` would expand to a set of patterns like:
|
||||
|
||||
[ [ a, d ]
|
||||
, [ b, c, d ] ]
|
||||
|
||||
If a portion of the pattern doesn't have any "magic" in it
|
||||
(that is, it's something like `"foo"` rather than `fo*o?`), then it
|
||||
will be left as a string rather than converted to a regular
|
||||
expression.
|
||||
|
||||
* `regexp` Created by the `makeRe` method. A single regular expression
|
||||
expressing the entire pattern. This is useful in cases where you wish
|
||||
to use the pattern somewhat like `fnmatch(3)` with `FNM_PATH` enabled.
|
||||
* `negate` True if the pattern is negated.
|
||||
* `comment` True if the pattern is a comment.
|
||||
* `empty` True if the pattern is `""`.
|
||||
|
||||
### Methods
|
||||
|
||||
* `makeRe` Generate the `regexp` member if necessary, and return it.
|
||||
Will return `false` if the pattern is invalid.
|
||||
* `match(fname)` Return true if the filename matches the pattern, or
|
||||
false otherwise.
|
||||
* `matchOne(fileArray, patternArray, partial)` Take a `/`-split
|
||||
filename, and match it against a single row in the `regExpSet`. This
|
||||
method is mainly for internal use, but is exposed so that it can be
|
||||
used by a glob-walker that needs to avoid excessive filesystem calls.
|
||||
|
||||
All other methods are internal, and will be called as necessary.
|
||||
|
||||
### minimatch(path, pattern, options)
|
||||
|
||||
Main export. Tests a path against the pattern using the options.
|
||||
|
||||
```javascript
|
||||
var isJS = minimatch(file, "*.js", { matchBase: true })
|
||||
```
|
||||
|
||||
### minimatch.filter(pattern, options)
|
||||
|
||||
Returns a function that tests its
|
||||
supplied argument, suitable for use with `Array.filter`. Example:
|
||||
|
||||
```javascript
|
||||
var javascripts = fileList.filter(minimatch.filter("*.js", {matchBase: true}))
|
||||
```
|
||||
|
||||
### minimatch.match(list, pattern, options)
|
||||
|
||||
Match against the list of
|
||||
files, in the style of fnmatch or glob. If nothing is matched, and
|
||||
options.nonull is set, then return a list containing the pattern itself.
|
||||
|
||||
```javascript
|
||||
var javascripts = minimatch.match(fileList, "*.js", {matchBase: true}))
|
||||
```
|
||||
|
||||
### minimatch.makeRe(pattern, options)
|
||||
|
||||
Make a regular expression object from the pattern.
|
||||
|
||||
## Options
|
||||
|
||||
All options are `false` by default.
|
||||
|
||||
### debug
|
||||
|
||||
Dump a ton of stuff to stderr.
|
||||
|
||||
### nobrace
|
||||
|
||||
Do not expand `{a,b}` and `{1..3}` brace sets.
|
||||
|
||||
### noglobstar
|
||||
|
||||
Disable `**` matching against multiple folder names.
|
||||
|
||||
### dot
|
||||
|
||||
Allow patterns to match filenames starting with a period, even if
|
||||
the pattern does not explicitly have a period in that spot.
|
||||
|
||||
Note that by default, `a/**/b` will **not** match `a/.d/b`, unless `dot`
|
||||
is set.
|
||||
|
||||
### noext
|
||||
|
||||
Disable "extglob" style patterns like `+(a|b)`.
|
||||
|
||||
### nocase
|
||||
|
||||
Perform a case-insensitive match.
|
||||
|
||||
### nonull
|
||||
|
||||
When a match is not found by `minimatch.match`, return a list containing
|
||||
the pattern itself if this option is set. When not set, an empty list
|
||||
is returned if there are no matches.
|
||||
|
||||
### matchBase
|
||||
|
||||
If set, then patterns without slashes will be matched
|
||||
against the basename of the path if it contains slashes. For example,
|
||||
`a?b` would match the path `/xyz/123/acb`, but not `/xyz/acb/123`.
|
||||
|
||||
### nocomment
|
||||
|
||||
Suppress the behavior of treating `#` at the start of a pattern as a
|
||||
comment.
|
||||
|
||||
### nonegate
|
||||
|
||||
Suppress the behavior of treating a leading `!` character as negation.
|
||||
|
||||
### flipNegate
|
||||
|
||||
Returns from negate expressions the same as if they were not negated.
|
||||
(Ie, true on a hit, false on a miss.)
|
||||
|
||||
|
||||
## Comparisons to other fnmatch/glob implementations
|
||||
|
||||
While strict compliance with the existing standards is a worthwhile
|
||||
goal, some discrepancies exist between minimatch and other
|
||||
implementations, and are intentional.
|
||||
|
||||
If the pattern starts with a `!` character, then it is negated. Set the
|
||||
`nonegate` flag to suppress this behavior, and treat leading `!`
|
||||
characters normally. This is perhaps relevant if you wish to start the
|
||||
pattern with a negative extglob pattern like `!(a|B)`. Multiple `!`
|
||||
characters at the start of a pattern will negate the pattern multiple
|
||||
times.
|
||||
|
||||
If a pattern starts with `#`, then it is treated as a comment, and
|
||||
will not match anything. Use `\#` to match a literal `#` at the
|
||||
start of a line, or set the `nocomment` flag to suppress this behavior.
|
||||
|
||||
The double-star character `**` is supported by default, unless the
|
||||
`noglobstar` flag is set. This is supported in the manner of bsdglob
|
||||
and bash 4.1, where `**` only has special significance if it is the only
|
||||
thing in a path part. That is, `a/**/b` will match `a/x/y/b`, but
|
||||
`a/**b` will not.
|
||||
|
||||
If an escaped pattern has no matches, and the `nonull` flag is set,
|
||||
then minimatch.match returns the pattern as-provided, rather than
|
||||
interpreting the character escapes. For example,
|
||||
`minimatch.match([], "\\*a\\?")` will return `"\\*a\\?"` rather than
|
||||
`"*a?"`. This is akin to setting the `nullglob` option in bash, except
|
||||
that it does not resolve escaped pattern characters.
|
||||
|
||||
If brace expansion is not disabled, then it is performed before any
|
||||
other interpretation of the glob pattern. Thus, a pattern like
|
||||
`+(a|{b),c)}`, which would not be valid in bash or zsh, is expanded
|
||||
**first** into the set of `+(a|b)` and `+(a|c)`, and those patterns are
|
||||
checked for validity. Since those two are valid, matching proceeds.
|
||||
923
node_modules/readdirp/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
923
node_modules/readdirp/node_modules/minimatch/minimatch.js
generated
vendored
Normal file
@@ -0,0 +1,923 @@
|
||||
module.exports = minimatch
|
||||
minimatch.Minimatch = Minimatch
|
||||
|
||||
var path = { sep: '/' }
|
||||
try {
|
||||
path = require('path')
|
||||
} catch (er) {}
|
||||
|
||||
var GLOBSTAR = minimatch.GLOBSTAR = Minimatch.GLOBSTAR = {}
|
||||
var expand = require('brace-expansion')
|
||||
|
||||
var plTypes = {
|
||||
'!': { open: '(?:(?!(?:', close: '))[^/]*?)'},
|
||||
'?': { open: '(?:', close: ')?' },
|
||||
'+': { open: '(?:', close: ')+' },
|
||||
'*': { open: '(?:', close: ')*' },
|
||||
'@': { open: '(?:', close: ')' }
|
||||
}
|
||||
|
||||
// any single thing other than /
|
||||
// don't need to escape / when using new RegExp()
|
||||
var qmark = '[^/]'
|
||||
|
||||
// * => any number of characters
|
||||
var star = qmark + '*?'
|
||||
|
||||
// ** when dots are allowed. Anything goes, except .. and .
|
||||
// not (^ or / followed by one or two dots followed by $ or /),
|
||||
// followed by anything, any number of times.
|
||||
var twoStarDot = '(?:(?!(?:\\\/|^)(?:\\.{1,2})($|\\\/)).)*?'
|
||||
|
||||
// not a ^ or / followed by a dot,
|
||||
// followed by anything, any number of times.
|
||||
var twoStarNoDot = '(?:(?!(?:\\\/|^)\\.).)*?'
|
||||
|
||||
// characters that need to be escaped in RegExp.
|
||||
var reSpecials = charSet('().*{}+?[]^$\\!')
|
||||
|
||||
// "abc" -> { a:true, b:true, c:true }
|
||||
function charSet (s) {
|
||||
return s.split('').reduce(function (set, c) {
|
||||
set[c] = true
|
||||
return set
|
||||
}, {})
|
||||
}
|
||||
|
||||
// normalizes slashes.
|
||||
var slashSplit = /\/+/
|
||||
|
||||
minimatch.filter = filter
|
||||
function filter (pattern, options) {
|
||||
options = options || {}
|
||||
return function (p, i, list) {
|
||||
return minimatch(p, pattern, options)
|
||||
}
|
||||
}
|
||||
|
||||
function ext (a, b) {
|
||||
a = a || {}
|
||||
b = b || {}
|
||||
var t = {}
|
||||
Object.keys(b).forEach(function (k) {
|
||||
t[k] = b[k]
|
||||
})
|
||||
Object.keys(a).forEach(function (k) {
|
||||
t[k] = a[k]
|
||||
})
|
||||
return t
|
||||
}
|
||||
|
||||
minimatch.defaults = function (def) {
|
||||
if (!def || !Object.keys(def).length) return minimatch
|
||||
|
||||
var orig = minimatch
|
||||
|
||||
var m = function minimatch (p, pattern, options) {
|
||||
return orig.minimatch(p, pattern, ext(def, options))
|
||||
}
|
||||
|
||||
m.Minimatch = function Minimatch (pattern, options) {
|
||||
return new orig.Minimatch(pattern, ext(def, options))
|
||||
}
|
||||
|
||||
return m
|
||||
}
|
||||
|
||||
Minimatch.defaults = function (def) {
|
||||
if (!def || !Object.keys(def).length) return Minimatch
|
||||
return minimatch.defaults(def).Minimatch
|
||||
}
|
||||
|
||||
function minimatch (p, pattern, options) {
|
||||
if (typeof pattern !== 'string') {
|
||||
throw new TypeError('glob pattern string required')
|
||||
}
|
||||
|
||||
if (!options) options = {}
|
||||
|
||||
// shortcut: comments match nothing.
|
||||
if (!options.nocomment && pattern.charAt(0) === '#') {
|
||||
return false
|
||||
}
|
||||
|
||||
// "" only matches ""
|
||||
if (pattern.trim() === '') return p === ''
|
||||
|
||||
return new Minimatch(pattern, options).match(p)
|
||||
}
|
||||
|
||||
function Minimatch (pattern, options) {
|
||||
if (!(this instanceof Minimatch)) {
|
||||
return new Minimatch(pattern, options)
|
||||
}
|
||||
|
||||
if (typeof pattern !== 'string') {
|
||||
throw new TypeError('glob pattern string required')
|
||||
}
|
||||
|
||||
if (!options) options = {}
|
||||
pattern = pattern.trim()
|
||||
|
||||
// windows support: need to use /, not \
|
||||
if (path.sep !== '/') {
|
||||
pattern = pattern.split(path.sep).join('/')
|
||||
}
|
||||
|
||||
this.options = options
|
||||
this.set = []
|
||||
this.pattern = pattern
|
||||
this.regexp = null
|
||||
this.negate = false
|
||||
this.comment = false
|
||||
this.empty = false
|
||||
|
||||
// make the set of regexps etc.
|
||||
this.make()
|
||||
}
|
||||
|
||||
Minimatch.prototype.debug = function () {}
|
||||
|
||||
Minimatch.prototype.make = make
|
||||
function make () {
|
||||
// don't do it more than once.
|
||||
if (this._made) return
|
||||
|
||||
var pattern = this.pattern
|
||||
var options = this.options
|
||||
|
||||
// empty patterns and comments match nothing.
|
||||
if (!options.nocomment && pattern.charAt(0) === '#') {
|
||||
this.comment = true
|
||||
return
|
||||
}
|
||||
if (!pattern) {
|
||||
this.empty = true
|
||||
return
|
||||
}
|
||||
|
||||
// step 1: figure out negation, etc.
|
||||
this.parseNegate()
|
||||
|
||||
// step 2: expand braces
|
||||
var set = this.globSet = this.braceExpand()
|
||||
|
||||
if (options.debug) this.debug = console.error
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// step 3: now we have a set, so turn each one into a series of path-portion
|
||||
// matching patterns.
|
||||
// These will be regexps, except in the case of "**", which is
|
||||
// set to the GLOBSTAR object for globstar behavior,
|
||||
// and will not contain any / characters
|
||||
set = this.globParts = set.map(function (s) {
|
||||
return s.split(slashSplit)
|
||||
})
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// glob --> regexps
|
||||
set = set.map(function (s, si, set) {
|
||||
return s.map(this.parse, this)
|
||||
}, this)
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
// filter out everything that didn't compile properly.
|
||||
set = set.filter(function (s) {
|
||||
return s.indexOf(false) === -1
|
||||
})
|
||||
|
||||
this.debug(this.pattern, set)
|
||||
|
||||
this.set = set
|
||||
}
|
||||
|
||||
Minimatch.prototype.parseNegate = parseNegate
|
||||
function parseNegate () {
|
||||
var pattern = this.pattern
|
||||
var negate = false
|
||||
var options = this.options
|
||||
var negateOffset = 0
|
||||
|
||||
if (options.nonegate) return
|
||||
|
||||
for (var i = 0, l = pattern.length
|
||||
; i < l && pattern.charAt(i) === '!'
|
||||
; i++) {
|
||||
negate = !negate
|
||||
negateOffset++
|
||||
}
|
||||
|
||||
if (negateOffset) this.pattern = pattern.substr(negateOffset)
|
||||
this.negate = negate
|
||||
}
|
||||
|
||||
// Brace expansion:
|
||||
// a{b,c}d -> abd acd
|
||||
// a{b,}c -> abc ac
|
||||
// a{0..3}d -> a0d a1d a2d a3d
|
||||
// a{b,c{d,e}f}g -> abg acdfg acefg
|
||||
// a{b,c}d{e,f}g -> abdeg acdeg abdeg abdfg
|
||||
//
|
||||
// Invalid sets are not expanded.
|
||||
// a{2..}b -> a{2..}b
|
||||
// a{b}c -> a{b}c
|
||||
minimatch.braceExpand = function (pattern, options) {
|
||||
return braceExpand(pattern, options)
|
||||
}
|
||||
|
||||
Minimatch.prototype.braceExpand = braceExpand
|
||||
|
||||
function braceExpand (pattern, options) {
|
||||
if (!options) {
|
||||
if (this instanceof Minimatch) {
|
||||
options = this.options
|
||||
} else {
|
||||
options = {}
|
||||
}
|
||||
}
|
||||
|
||||
pattern = typeof pattern === 'undefined'
|
||||
? this.pattern : pattern
|
||||
|
||||
if (typeof pattern === 'undefined') {
|
||||
throw new TypeError('undefined pattern')
|
||||
}
|
||||
|
||||
if (options.nobrace ||
|
||||
!pattern.match(/\{.*\}/)) {
|
||||
// shortcut. no need to expand.
|
||||
return [pattern]
|
||||
}
|
||||
|
||||
return expand(pattern)
|
||||
}
|
||||
|
||||
// parse a component of the expanded set.
|
||||
// At this point, no pattern may contain "/" in it
|
||||
// so we're going to return a 2d array, where each entry is the full
|
||||
// pattern, split on '/', and then turned into a regular expression.
|
||||
// A regexp is made at the end which joins each array with an
|
||||
// escaped /, and another full one which joins each regexp with |.
|
||||
//
|
||||
// Following the lead of Bash 4.1, note that "**" only has special meaning
|
||||
// when it is the *only* thing in a path portion. Otherwise, any series
|
||||
// of * is equivalent to a single *. Globstar behavior is enabled by
|
||||
// default, and can be disabled by setting options.noglobstar.
|
||||
Minimatch.prototype.parse = parse
|
||||
var SUBPARSE = {}
|
||||
function parse (pattern, isSub) {
|
||||
if (pattern.length > 1024 * 64) {
|
||||
throw new TypeError('pattern is too long')
|
||||
}
|
||||
|
||||
var options = this.options
|
||||
|
||||
// shortcuts
|
||||
if (!options.noglobstar && pattern === '**') return GLOBSTAR
|
||||
if (pattern === '') return ''
|
||||
|
||||
var re = ''
|
||||
var hasMagic = !!options.nocase
|
||||
var escaping = false
|
||||
// ? => one single character
|
||||
var patternListStack = []
|
||||
var negativeLists = []
|
||||
var stateChar
|
||||
var inClass = false
|
||||
var reClassStart = -1
|
||||
var classStart = -1
|
||||
// . and .. never match anything that doesn't start with .,
|
||||
// even when options.dot is set.
|
||||
var patternStart = pattern.charAt(0) === '.' ? '' // anything
|
||||
// not (start or / followed by . or .. followed by / or end)
|
||||
: options.dot ? '(?!(?:^|\\\/)\\.{1,2}(?:$|\\\/))'
|
||||
: '(?!\\.)'
|
||||
var self = this
|
||||
|
||||
function clearStateChar () {
|
||||
if (stateChar) {
|
||||
// we had some state-tracking character
|
||||
// that wasn't consumed by this pass.
|
||||
switch (stateChar) {
|
||||
case '*':
|
||||
re += star
|
||||
hasMagic = true
|
||||
break
|
||||
case '?':
|
||||
re += qmark
|
||||
hasMagic = true
|
||||
break
|
||||
default:
|
||||
re += '\\' + stateChar
|
||||
break
|
||||
}
|
||||
self.debug('clearStateChar %j %j', stateChar, re)
|
||||
stateChar = false
|
||||
}
|
||||
}
|
||||
|
||||
for (var i = 0, len = pattern.length, c
|
||||
; (i < len) && (c = pattern.charAt(i))
|
||||
; i++) {
|
||||
this.debug('%s\t%s %s %j', pattern, i, re, c)
|
||||
|
||||
// skip over any that are escaped.
|
||||
if (escaping && reSpecials[c]) {
|
||||
re += '\\' + c
|
||||
escaping = false
|
||||
continue
|
||||
}
|
||||
|
||||
switch (c) {
|
||||
case '/':
|
||||
// completely not allowed, even escaped.
|
||||
// Should already be path-split by now.
|
||||
return false
|
||||
|
||||
case '\\':
|
||||
clearStateChar()
|
||||
escaping = true
|
||||
continue
|
||||
|
||||
// the various stateChar values
|
||||
// for the "extglob" stuff.
|
||||
case '?':
|
||||
case '*':
|
||||
case '+':
|
||||
case '@':
|
||||
case '!':
|
||||
this.debug('%s\t%s %s %j <-- stateChar', pattern, i, re, c)
|
||||
|
||||
// all of those are literals inside a class, except that
|
||||
// the glob [!a] means [^a] in regexp
|
||||
if (inClass) {
|
||||
this.debug(' in class')
|
||||
if (c === '!' && i === classStart + 1) c = '^'
|
||||
re += c
|
||||
continue
|
||||
}
|
||||
|
||||
// if we already have a stateChar, then it means
|
||||
// that there was something like ** or +? in there.
|
||||
// Handle the stateChar, then proceed with this one.
|
||||
self.debug('call clearStateChar %j', stateChar)
|
||||
clearStateChar()
|
||||
stateChar = c
|
||||
// if extglob is disabled, then +(asdf|foo) isn't a thing.
|
||||
// just clear the statechar *now*, rather than even diving into
|
||||
// the patternList stuff.
|
||||
if (options.noext) clearStateChar()
|
||||
continue
|
||||
|
||||
case '(':
|
||||
if (inClass) {
|
||||
re += '('
|
||||
continue
|
||||
}
|
||||
|
||||
if (!stateChar) {
|
||||
re += '\\('
|
||||
continue
|
||||
}
|
||||
|
||||
patternListStack.push({
|
||||
type: stateChar,
|
||||
start: i - 1,
|
||||
reStart: re.length,
|
||||
open: plTypes[stateChar].open,
|
||||
close: plTypes[stateChar].close
|
||||
})
|
||||
// negation is (?:(?!js)[^/]*)
|
||||
re += stateChar === '!' ? '(?:(?!(?:' : '(?:'
|
||||
this.debug('plType %j %j', stateChar, re)
|
||||
stateChar = false
|
||||
continue
|
||||
|
||||
case ')':
|
||||
if (inClass || !patternListStack.length) {
|
||||
re += '\\)'
|
||||
continue
|
||||
}
|
||||
|
||||
clearStateChar()
|
||||
hasMagic = true
|
||||
var pl = patternListStack.pop()
|
||||
// negation is (?:(?!js)[^/]*)
|
||||
// The others are (?:<pattern>)<type>
|
||||
re += pl.close
|
||||
if (pl.type === '!') {
|
||||
negativeLists.push(pl)
|
||||
}
|
||||
pl.reEnd = re.length
|
||||
continue
|
||||
|
||||
case '|':
|
||||
if (inClass || !patternListStack.length || escaping) {
|
||||
re += '\\|'
|
||||
escaping = false
|
||||
continue
|
||||
}
|
||||
|
||||
clearStateChar()
|
||||
re += '|'
|
||||
continue
|
||||
|
||||
// these are mostly the same in regexp and glob
|
||||
case '[':
|
||||
// swallow any state-tracking char before the [
|
||||
clearStateChar()
|
||||
|
||||
if (inClass) {
|
||||
re += '\\' + c
|
||||
continue
|
||||
}
|
||||
|
||||
inClass = true
|
||||
classStart = i
|
||||
reClassStart = re.length
|
||||
re += c
|
||||
continue
|
||||
|
||||
case ']':
|
||||
// a right bracket shall lose its special
|
||||
// meaning and represent itself in
|
||||
// a bracket expression if it occurs
|
||||
// first in the list. -- POSIX.2 2.8.3.2
|
||||
if (i === classStart + 1 || !inClass) {
|
||||
re += '\\' + c
|
||||
escaping = false
|
||||
continue
|
||||
}
|
||||
|
||||
// handle the case where we left a class open.
|
||||
// "[z-a]" is valid, equivalent to "\[z-a\]"
|
||||
if (inClass) {
|
||||
// split where the last [ was, make sure we don't have
|
||||
// an invalid re. if so, re-walk the contents of the
|
||||
// would-be class to re-translate any characters that
|
||||
// were passed through as-is
|
||||
// TODO: It would probably be faster to determine this
|
||||
// without a try/catch and a new RegExp, but it's tricky
|
||||
// to do safely. For now, this is safe and works.
|
||||
var cs = pattern.substring(classStart + 1, i)
|
||||
try {
|
||||
RegExp('[' + cs + ']')
|
||||
} catch (er) {
|
||||
// not a valid class!
|
||||
var sp = this.parse(cs, SUBPARSE)
|
||||
re = re.substr(0, reClassStart) + '\\[' + sp[0] + '\\]'
|
||||
hasMagic = hasMagic || sp[1]
|
||||
inClass = false
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
// finish up the class.
|
||||
hasMagic = true
|
||||
inClass = false
|
||||
re += c
|
||||
continue
|
||||
|
||||
default:
|
||||
// swallow any state char that wasn't consumed
|
||||
clearStateChar()
|
||||
|
||||
if (escaping) {
|
||||
// no need
|
||||
escaping = false
|
||||
} else if (reSpecials[c]
|
||||
&& !(c === '^' && inClass)) {
|
||||
re += '\\'
|
||||
}
|
||||
|
||||
re += c
|
||||
|
||||
} // switch
|
||||
} // for
|
||||
|
||||
// handle the case where we left a class open.
|
||||
// "[abc" is valid, equivalent to "\[abc"
|
||||
if (inClass) {
|
||||
// split where the last [ was, and escape it
|
||||
// this is a huge pita. We now have to re-walk
|
||||
// the contents of the would-be class to re-translate
|
||||
// any characters that were passed through as-is
|
||||
cs = pattern.substr(classStart + 1)
|
||||
sp = this.parse(cs, SUBPARSE)
|
||||
re = re.substr(0, reClassStart) + '\\[' + sp[0]
|
||||
hasMagic = hasMagic || sp[1]
|
||||
}
|
||||
|
||||
// handle the case where we had a +( thing at the *end*
|
||||
// of the pattern.
|
||||
// each pattern list stack adds 3 chars, and we need to go through
|
||||
// and escape any | chars that were passed through as-is for the regexp.
|
||||
// Go through and escape them, taking care not to double-escape any
|
||||
// | chars that were already escaped.
|
||||
for (pl = patternListStack.pop(); pl; pl = patternListStack.pop()) {
|
||||
var tail = re.slice(pl.reStart + pl.open.length)
|
||||
this.debug('setting tail', re, pl)
|
||||
// maybe some even number of \, then maybe 1 \, followed by a |
|
||||
tail = tail.replace(/((?:\\{2}){0,64})(\\?)\|/g, function (_, $1, $2) {
|
||||
if (!$2) {
|
||||
// the | isn't already escaped, so escape it.
|
||||
$2 = '\\'
|
||||
}
|
||||
|
||||
// need to escape all those slashes *again*, without escaping the
|
||||
// one that we need for escaping the | character. As it works out,
|
||||
// escaping an even number of slashes can be done by simply repeating
|
||||
// it exactly after itself. That's why this trick works.
|
||||
//
|
||||
// I am sorry that you have to see this.
|
||||
return $1 + $1 + $2 + '|'
|
||||
})
|
||||
|
||||
this.debug('tail=%j\n %s', tail, tail, pl, re)
|
||||
var t = pl.type === '*' ? star
|
||||
: pl.type === '?' ? qmark
|
||||
: '\\' + pl.type
|
||||
|
||||
hasMagic = true
|
||||
re = re.slice(0, pl.reStart) + t + '\\(' + tail
|
||||
}
|
||||
|
||||
// handle trailing things that only matter at the very end.
|
||||
clearStateChar()
|
||||
if (escaping) {
|
||||
// trailing \\
|
||||
re += '\\\\'
|
||||
}
|
||||
|
||||
// only need to apply the nodot start if the re starts with
|
||||
// something that could conceivably capture a dot
|
||||
var addPatternStart = false
|
||||
switch (re.charAt(0)) {
|
||||
case '.':
|
||||
case '[':
|
||||
case '(': addPatternStart = true
|
||||
}
|
||||
|
||||
// Hack to work around lack of negative lookbehind in JS
|
||||
// A pattern like: *.!(x).!(y|z) needs to ensure that a name
|
||||
// like 'a.xyz.yz' doesn't match. So, the first negative
|
||||
// lookahead, has to look ALL the way ahead, to the end of
|
||||
// the pattern.
|
||||
for (var n = negativeLists.length - 1; n > -1; n--) {
|
||||
var nl = negativeLists[n]
|
||||
|
||||
var nlBefore = re.slice(0, nl.reStart)
|
||||
var nlFirst = re.slice(nl.reStart, nl.reEnd - 8)
|
||||
var nlLast = re.slice(nl.reEnd - 8, nl.reEnd)
|
||||
var nlAfter = re.slice(nl.reEnd)
|
||||
|
||||
nlLast += nlAfter
|
||||
|
||||
// Handle nested stuff like *(*.js|!(*.json)), where open parens
|
||||
// mean that we should *not* include the ) in the bit that is considered
|
||||
// "after" the negated section.
|
||||
var openParensBefore = nlBefore.split('(').length - 1
|
||||
var cleanAfter = nlAfter
|
||||
for (i = 0; i < openParensBefore; i++) {
|
||||
cleanAfter = cleanAfter.replace(/\)[+*?]?/, '')
|
||||
}
|
||||
nlAfter = cleanAfter
|
||||
|
||||
var dollar = ''
|
||||
if (nlAfter === '' && isSub !== SUBPARSE) {
|
||||
dollar = '$'
|
||||
}
|
||||
var newRe = nlBefore + nlFirst + nlAfter + dollar + nlLast
|
||||
re = newRe
|
||||
}
|
||||
|
||||
// if the re is not "" at this point, then we need to make sure
|
||||
// it doesn't match against an empty path part.
|
||||
// Otherwise a/* will match a/, which it should not.
|
||||
if (re !== '' && hasMagic) {
|
||||
re = '(?=.)' + re
|
||||
}
|
||||
|
||||
if (addPatternStart) {
|
||||
re = patternStart + re
|
||||
}
|
||||
|
||||
// parsing just a piece of a larger pattern.
|
||||
if (isSub === SUBPARSE) {
|
||||
return [re, hasMagic]
|
||||
}
|
||||
|
||||
// skip the regexp for non-magical patterns
|
||||
// unescape anything in it, though, so that it'll be
|
||||
// an exact match against a file etc.
|
||||
if (!hasMagic) {
|
||||
return globUnescape(pattern)
|
||||
}
|
||||
|
||||
var flags = options.nocase ? 'i' : ''
|
||||
try {
|
||||
var regExp = new RegExp('^' + re + '$', flags)
|
||||
} catch (er) {
|
||||
// If it was an invalid regular expression, then it can't match
|
||||
// anything. This trick looks for a character after the end of
|
||||
// the string, which is of course impossible, except in multi-line
|
||||
// mode, but it's not a /m regex.
|
||||
return new RegExp('$.')
|
||||
}
|
||||
|
||||
regExp._glob = pattern
|
||||
regExp._src = re
|
||||
|
||||
return regExp
|
||||
}
|
||||
|
||||
minimatch.makeRe = function (pattern, options) {
|
||||
return new Minimatch(pattern, options || {}).makeRe()
|
||||
}
|
||||
|
||||
Minimatch.prototype.makeRe = makeRe
|
||||
function makeRe () {
|
||||
if (this.regexp || this.regexp === false) return this.regexp
|
||||
|
||||
// at this point, this.set is a 2d array of partial
|
||||
// pattern strings, or "**".
|
||||
//
|
||||
// It's better to use .match(). This function shouldn't
|
||||
// be used, really, but it's pretty convenient sometimes,
|
||||
// when you just want to work with a regex.
|
||||
var set = this.set
|
||||
|
||||
if (!set.length) {
|
||||
this.regexp = false
|
||||
return this.regexp
|
||||
}
|
||||
var options = this.options
|
||||
|
||||
var twoStar = options.noglobstar ? star
|
||||
: options.dot ? twoStarDot
|
||||
: twoStarNoDot
|
||||
var flags = options.nocase ? 'i' : ''
|
||||
|
||||
var re = set.map(function (pattern) {
|
||||
return pattern.map(function (p) {
|
||||
return (p === GLOBSTAR) ? twoStar
|
||||
: (typeof p === 'string') ? regExpEscape(p)
|
||||
: p._src
|
||||
}).join('\\\/')
|
||||
}).join('|')
|
||||
|
||||
// must match entire pattern
|
||||
// ending in a * or ** will make it less strict.
|
||||
re = '^(?:' + re + ')$'
|
||||
|
||||
// can match anything, as long as it's not this.
|
||||
if (this.negate) re = '^(?!' + re + ').*$'
|
||||
|
||||
try {
|
||||
this.regexp = new RegExp(re, flags)
|
||||
} catch (ex) {
|
||||
this.regexp = false
|
||||
}
|
||||
return this.regexp
|
||||
}
|
||||
|
||||
minimatch.match = function (list, pattern, options) {
|
||||
options = options || {}
|
||||
var mm = new Minimatch(pattern, options)
|
||||
list = list.filter(function (f) {
|
||||
return mm.match(f)
|
||||
})
|
||||
if (mm.options.nonull && !list.length) {
|
||||
list.push(pattern)
|
||||
}
|
||||
return list
|
||||
}
|
||||
|
||||
Minimatch.prototype.match = match
|
||||
function match (f, partial) {
|
||||
this.debug('match', f, this.pattern)
|
||||
// short-circuit in the case of busted things.
|
||||
// comments, etc.
|
||||
if (this.comment) return false
|
||||
if (this.empty) return f === ''
|
||||
|
||||
if (f === '/' && partial) return true
|
||||
|
||||
var options = this.options
|
||||
|
||||
// windows: need to use /, not \
|
||||
if (path.sep !== '/') {
|
||||
f = f.split(path.sep).join('/')
|
||||
}
|
||||
|
||||
// treat the test path as a set of pathparts.
|
||||
f = f.split(slashSplit)
|
||||
this.debug(this.pattern, 'split', f)
|
||||
|
||||
// just ONE of the pattern sets in this.set needs to match
|
||||
// in order for it to be valid. If negating, then just one
|
||||
// match means that we have failed.
|
||||
// Either way, return on the first hit.
|
||||
|
||||
var set = this.set
|
||||
this.debug(this.pattern, 'set', set)
|
||||
|
||||
// Find the basename of the path by looking for the last non-empty segment
|
||||
var filename
|
||||
var i
|
||||
for (i = f.length - 1; i >= 0; i--) {
|
||||
filename = f[i]
|
||||
if (filename) break
|
||||
}
|
||||
|
||||
for (i = 0; i < set.length; i++) {
|
||||
var pattern = set[i]
|
||||
var file = f
|
||||
if (options.matchBase && pattern.length === 1) {
|
||||
file = [filename]
|
||||
}
|
||||
var hit = this.matchOne(file, pattern, partial)
|
||||
if (hit) {
|
||||
if (options.flipNegate) return true
|
||||
return !this.negate
|
||||
}
|
||||
}
|
||||
|
||||
// didn't get any hits. this is success if it's a negative
|
||||
// pattern, failure otherwise.
|
||||
if (options.flipNegate) return false
|
||||
return this.negate
|
||||
}
|
||||
|
||||
// set partial to true to test if, for example,
|
||||
// "/a/b" matches the start of "/*/b/*/d"
|
||||
// Partial means, if you run out of file before you run
|
||||
// out of pattern, then that's fine, as long as all
|
||||
// the parts match.
|
||||
Minimatch.prototype.matchOne = function (file, pattern, partial) {
|
||||
var options = this.options
|
||||
|
||||
this.debug('matchOne',
|
||||
{ 'this': this, file: file, pattern: pattern })
|
||||
|
||||
this.debug('matchOne', file.length, pattern.length)
|
||||
|
||||
for (var fi = 0,
|
||||
pi = 0,
|
||||
fl = file.length,
|
||||
pl = pattern.length
|
||||
; (fi < fl) && (pi < pl)
|
||||
; fi++, pi++) {
|
||||
this.debug('matchOne loop')
|
||||
var p = pattern[pi]
|
||||
var f = file[fi]
|
||||
|
||||
this.debug(pattern, p, f)
|
||||
|
||||
// should be impossible.
|
||||
// some invalid regexp stuff in the set.
|
||||
if (p === false) return false
|
||||
|
||||
if (p === GLOBSTAR) {
|
||||
this.debug('GLOBSTAR', [pattern, p, f])
|
||||
|
||||
// "**"
|
||||
// a/**/b/**/c would match the following:
|
||||
// a/b/x/y/z/c
|
||||
// a/x/y/z/b/c
|
||||
// a/b/x/b/x/c
|
||||
// a/b/c
|
||||
// To do this, take the rest of the pattern after
|
||||
// the **, and see if it would match the file remainder.
|
||||
// If so, return success.
|
||||
// If not, the ** "swallows" a segment, and try again.
|
||||
// This is recursively awful.
|
||||
//
|
||||
// a/**/b/**/c matching a/b/x/y/z/c
|
||||
// - a matches a
|
||||
// - doublestar
|
||||
// - matchOne(b/x/y/z/c, b/**/c)
|
||||
// - b matches b
|
||||
// - doublestar
|
||||
// - matchOne(x/y/z/c, c) -> no
|
||||
// - matchOne(y/z/c, c) -> no
|
||||
// - matchOne(z/c, c) -> no
|
||||
// - matchOne(c, c) yes, hit
|
||||
var fr = fi
|
||||
var pr = pi + 1
|
||||
if (pr === pl) {
|
||||
this.debug('** at the end')
|
||||
// a ** at the end will just swallow the rest.
|
||||
// We have found a match.
|
||||
// however, it will not swallow /.x, unless
|
||||
// options.dot is set.
|
||||
// . and .. are *never* matched by **, for explosively
|
||||
// exponential reasons.
|
||||
for (; fi < fl; fi++) {
|
||||
if (file[fi] === '.' || file[fi] === '..' ||
|
||||
(!options.dot && file[fi].charAt(0) === '.')) return false
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
// ok, let's see if we can swallow whatever we can.
|
||||
while (fr < fl) {
|
||||
var swallowee = file[fr]
|
||||
|
||||
this.debug('\nglobstar while', file, fr, pattern, pr, swallowee)
|
||||
|
||||
// XXX remove this slice. Just pass the start index.
|
||||
if (this.matchOne(file.slice(fr), pattern.slice(pr), partial)) {
|
||||
this.debug('globstar found match!', fr, fl, swallowee)
|
||||
// found a match.
|
||||
return true
|
||||
} else {
|
||||
// can't swallow "." or ".." ever.
|
||||
// can only swallow ".foo" when explicitly asked.
|
||||
if (swallowee === '.' || swallowee === '..' ||
|
||||
(!options.dot && swallowee.charAt(0) === '.')) {
|
||||
this.debug('dot detected!', file, fr, pattern, pr)
|
||||
break
|
||||
}
|
||||
|
||||
// ** swallows a segment, and continue.
|
||||
this.debug('globstar swallow a segment, and continue')
|
||||
fr++
|
||||
}
|
||||
}
|
||||
|
||||
// no match was found.
|
||||
// However, in partial mode, we can't say this is necessarily over.
|
||||
// If there's more *pattern* left, then
|
||||
if (partial) {
|
||||
// ran out of file
|
||||
this.debug('\n>>> no match, partial?', file, fr, pattern, pr)
|
||||
if (fr === fl) return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// something other than **
|
||||
// non-magic patterns just have to match exactly
|
||||
// patterns with magic have been turned into regexps.
|
||||
var hit
|
||||
if (typeof p === 'string') {
|
||||
if (options.nocase) {
|
||||
hit = f.toLowerCase() === p.toLowerCase()
|
||||
} else {
|
||||
hit = f === p
|
||||
}
|
||||
this.debug('string match', p, f, hit)
|
||||
} else {
|
||||
hit = f.match(p)
|
||||
this.debug('pattern match', p, f, hit)
|
||||
}
|
||||
|
||||
if (!hit) return false
|
||||
}
|
||||
|
||||
// Note: ending in / means that we'll get a final ""
|
||||
// at the end of the pattern. This can only match a
|
||||
// corresponding "" at the end of the file.
|
||||
// If the file ends in /, then it can only match a
|
||||
// a pattern that ends in /, unless the pattern just
|
||||
// doesn't have any more for it. But, a/b/ should *not*
|
||||
// match "a/b/*", even though "" matches against the
|
||||
// [^/]*? pattern, except in partial mode, where it might
|
||||
// simply not be reached yet.
|
||||
// However, a/b/ should still satisfy a/*
|
||||
|
||||
// now either we fell off the end of the pattern, or we're done.
|
||||
if (fi === fl && pi === pl) {
|
||||
// ran out of pattern and filename at the same time.
|
||||
// an exact hit!
|
||||
return true
|
||||
} else if (fi === fl) {
|
||||
// ran out of file, but still had pattern left.
|
||||
// this is ok if we're doing the match as part of
|
||||
// a glob fs traversal.
|
||||
return partial
|
||||
} else if (pi === pl) {
|
||||
// ran out of pattern, still have file left.
|
||||
// this is only acceptable if we're on the very last
|
||||
// empty segment of a file with a trailing slash.
|
||||
// a/* should match a/b/
|
||||
var emptyFileEnd = (fi === fl - 1) && (file[fi] === '')
|
||||
return emptyFileEnd
|
||||
}
|
||||
|
||||
// should be unreachable.
|
||||
throw new Error('wtf?')
|
||||
}
|
||||
|
||||
// replace stuff like \* with *
|
||||
function globUnescape (s) {
|
||||
return s.replace(/\\(.)/g, '$1')
|
||||
}
|
||||
|
||||
function regExpEscape (s) {
|
||||
return s.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, '\\$&')
|
||||
}
|
||||
111
node_modules/readdirp/node_modules/minimatch/package.json
generated
vendored
Normal file
111
node_modules/readdirp/node_modules/minimatch/package.json
generated
vendored
Normal file
@@ -0,0 +1,111 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "minimatch@^3.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "minimatch",
|
||||
"name": "minimatch",
|
||||
"rawSpec": "^3.0.0",
|
||||
"spec": ">=3.0.0 <4.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\nodemon"
|
||||
],
|
||||
[
|
||||
{
|
||||
"raw": "minimatch@^3.0.2",
|
||||
"scope": null,
|
||||
"escapedName": "minimatch",
|
||||
"name": "minimatch",
|
||||
"rawSpec": "^3.0.2",
|
||||
"spec": ">=3.0.2 <4.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp"
|
||||
]
|
||||
],
|
||||
"_from": "minimatch@^3.0.2",
|
||||
"_id": "minimatch@3.0.4",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp/minimatch",
|
||||
"_nodeVersion": "8.0.0-pre",
|
||||
"_npmOperationalInternal": {
|
||||
"host": "packages-18-east.internal.npmjs.com",
|
||||
"tmp": "tmp/minimatch-3.0.4.tgz_1494180669024_0.22628829116001725"
|
||||
},
|
||||
"_npmUser": {
|
||||
"name": "isaacs",
|
||||
"email": "i@izs.me"
|
||||
},
|
||||
"_npmVersion": "5.0.0-beta.43",
|
||||
"_phantomChildren": {},
|
||||
"_requested": {
|
||||
"raw": "minimatch@^3.0.2",
|
||||
"scope": null,
|
||||
"escapedName": "minimatch",
|
||||
"name": "minimatch",
|
||||
"rawSpec": "^3.0.2",
|
||||
"spec": ">=3.0.2 <4.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/readdirp"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz",
|
||||
"_shasum": "5166e286457f03306064be5497e8dbb0c3d32083",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "minimatch@^3.0.2",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp",
|
||||
"author": {
|
||||
"name": "Isaac Z. Schlueter",
|
||||
"email": "i@izs.me",
|
||||
"url": "http://blog.izs.me"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/isaacs/minimatch/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"brace-expansion": "^1.1.7"
|
||||
},
|
||||
"description": "a glob matcher in javascript",
|
||||
"devDependencies": {
|
||||
"tap": "^10.3.2"
|
||||
},
|
||||
"directories": {},
|
||||
"dist": {
|
||||
"integrity": "sha512-yJHVQEhyqPLUTgt9B83PXu6W3rx4MvvHvSUvToogpwoGDOUQ+yDrR0HRot+yOCdCO7u4hX3pWft6kWBBcqh0UA==",
|
||||
"shasum": "5166e286457f03306064be5497e8dbb0c3d32083",
|
||||
"tarball": "https://registry.npmjs.org/minimatch/-/minimatch-3.0.4.tgz"
|
||||
},
|
||||
"engines": {
|
||||
"node": "*"
|
||||
},
|
||||
"files": [
|
||||
"minimatch.js"
|
||||
],
|
||||
"gitHead": "e46989a323d5f0aa4781eff5e2e6e7aafa223321",
|
||||
"homepage": "https://github.com/isaacs/minimatch#readme",
|
||||
"license": "ISC",
|
||||
"main": "minimatch.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "isaacs",
|
||||
"email": "i@izs.me"
|
||||
}
|
||||
],
|
||||
"name": "minimatch",
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/isaacs/minimatch.git"
|
||||
},
|
||||
"scripts": {
|
||||
"postpublish": "git push origin --all; git push origin --tags",
|
||||
"postversion": "npm publish",
|
||||
"preversion": "npm test",
|
||||
"test": "tap test/*.js --cov"
|
||||
},
|
||||
"version": "3.0.4"
|
||||
}
|
||||
9
node_modules/readdirp/node_modules/readable-stream/.npmignore
generated
vendored
Normal file
9
node_modules/readdirp/node_modules/readable-stream/.npmignore
generated
vendored
Normal file
@@ -0,0 +1,9 @@
|
||||
build/
|
||||
test/
|
||||
examples/
|
||||
fs.js
|
||||
zlib.js
|
||||
.zuul.yml
|
||||
.nyc_output
|
||||
coverage
|
||||
docs/
|
||||
49
node_modules/readdirp/node_modules/readable-stream/.travis.yml
generated
vendored
Normal file
49
node_modules/readdirp/node_modules/readable-stream/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,49 @@
|
||||
sudo: false
|
||||
language: node_js
|
||||
before_install:
|
||||
- npm install -g npm@2
|
||||
- npm install -g npm
|
||||
notifications:
|
||||
email: false
|
||||
matrix:
|
||||
fast_finish: true
|
||||
include:
|
||||
- node_js: '0.8'
|
||||
env: TASK=test
|
||||
- node_js: '0.10'
|
||||
env: TASK=test
|
||||
- node_js: '0.11'
|
||||
env: TASK=test
|
||||
- node_js: '0.12'
|
||||
env: TASK=test
|
||||
- node_js: 1
|
||||
env: TASK=test
|
||||
- node_js: 2
|
||||
env: TASK=test
|
||||
- node_js: 3
|
||||
env: TASK=test
|
||||
- node_js: 4
|
||||
env: TASK=test
|
||||
- node_js: 5
|
||||
env: TASK=test
|
||||
- node_js: 6
|
||||
env: TASK=test
|
||||
- node_js: 7
|
||||
env: TASK=test
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=ie BROWSER_VERSION="9..latest"
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=opera BROWSER_VERSION="11..latest"
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=chrome BROWSER_VERSION="-3..latest"
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=firefox BROWSER_VERSION="-3..latest"
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=safari BROWSER_VERSION="5..latest"
|
||||
- node_js: 5
|
||||
env: TASK=browser BROWSER_NAME=microsoftedge BROWSER_VERSION=latest
|
||||
script: "npm run $TASK"
|
||||
env:
|
||||
global:
|
||||
- secure: rE2Vvo7vnjabYNULNyLFxOyt98BoJexDqsiOnfiD6kLYYsiQGfr/sbZkPMOFm9qfQG7pjqx+zZWZjGSswhTt+626C0t/njXqug7Yps4c3dFblzGfreQHp7wNX5TFsvrxd6dAowVasMp61sJcRnB2w8cUzoe3RAYUDHyiHktwqMc=
|
||||
- secure: g9YINaKAdMatsJ28G9jCGbSaguXCyxSTy+pBO6Ch0Cf57ZLOTka3HqDj8p3nV28LUIHZ3ut5WO43CeYKwt4AUtLpBS3a0dndHdY6D83uY6b2qh5hXlrcbeQTq2cvw2y95F7hm4D1kwrgZ7ViqaKggRcEupAL69YbJnxeUDKWEdI=
|
||||
38
node_modules/readdirp/node_modules/readable-stream/CONTRIBUTING.md
generated
vendored
Normal file
38
node_modules/readdirp/node_modules/readable-stream/CONTRIBUTING.md
generated
vendored
Normal file
@@ -0,0 +1,38 @@
|
||||
# Developer's Certificate of Origin 1.1
|
||||
|
||||
By making a contribution to this project, I certify that:
|
||||
|
||||
* (a) The contribution was created in whole or in part by me and I
|
||||
have the right to submit it under the open source license
|
||||
indicated in the file; or
|
||||
|
||||
* (b) The contribution is based upon previous work that, to the best
|
||||
of my knowledge, is covered under an appropriate open source
|
||||
license and I have the right under that license to submit that
|
||||
work with modifications, whether created in whole or in part
|
||||
by me, under the same open source license (unless I am
|
||||
permitted to submit under a different license), as indicated
|
||||
in the file; or
|
||||
|
||||
* (c) The contribution was provided directly to me by some other
|
||||
person who certified (a), (b) or (c) and I have not modified
|
||||
it.
|
||||
|
||||
* (d) I understand and agree that this project and the contribution
|
||||
are public and that a record of the contribution (including all
|
||||
personal information I submit with it, including my sign-off) is
|
||||
maintained indefinitely and may be redistributed consistent with
|
||||
this project or the open source license(s) involved.
|
||||
|
||||
## Moderation Policy
|
||||
|
||||
The [Node.js Moderation Policy] applies to this WG.
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
The [Node.js Code of Conduct][] applies to this WG.
|
||||
|
||||
[Node.js Code of Conduct]:
|
||||
https://github.com/nodejs/node/blob/master/CODE_OF_CONDUCT.md
|
||||
[Node.js Moderation Policy]:
|
||||
https://github.com/nodejs/TSC/blob/master/Moderation-Policy.md
|
||||
136
node_modules/readdirp/node_modules/readable-stream/GOVERNANCE.md
generated
vendored
Normal file
136
node_modules/readdirp/node_modules/readable-stream/GOVERNANCE.md
generated
vendored
Normal file
@@ -0,0 +1,136 @@
|
||||
### Streams Working Group
|
||||
|
||||
The Node.js Streams is jointly governed by a Working Group
|
||||
(WG)
|
||||
that is responsible for high-level guidance of the project.
|
||||
|
||||
The WG has final authority over this project including:
|
||||
|
||||
* Technical direction
|
||||
* Project governance and process (including this policy)
|
||||
* Contribution policy
|
||||
* GitHub repository hosting
|
||||
* Conduct guidelines
|
||||
* Maintaining the list of additional Collaborators
|
||||
|
||||
For the current list of WG members, see the project
|
||||
[README.md](./README.md#current-project-team-members).
|
||||
|
||||
### Collaborators
|
||||
|
||||
The readable-stream GitHub repository is
|
||||
maintained by the WG and additional Collaborators who are added by the
|
||||
WG on an ongoing basis.
|
||||
|
||||
Individuals making significant and valuable contributions are made
|
||||
Collaborators and given commit-access to the project. These
|
||||
individuals are identified by the WG and their addition as
|
||||
Collaborators is discussed during the WG meeting.
|
||||
|
||||
_Note:_ If you make a significant contribution and are not considered
|
||||
for commit-access log an issue or contact a WG member directly and it
|
||||
will be brought up in the next WG meeting.
|
||||
|
||||
Modifications of the contents of the readable-stream repository are
|
||||
made on
|
||||
a collaborative basis. Anybody with a GitHub account may propose a
|
||||
modification via pull request and it will be considered by the project
|
||||
Collaborators. All pull requests must be reviewed and accepted by a
|
||||
Collaborator with sufficient expertise who is able to take full
|
||||
responsibility for the change. In the case of pull requests proposed
|
||||
by an existing Collaborator, an additional Collaborator is required
|
||||
for sign-off. Consensus should be sought if additional Collaborators
|
||||
participate and there is disagreement around a particular
|
||||
modification. See _Consensus Seeking Process_ below for further detail
|
||||
on the consensus model used for governance.
|
||||
|
||||
Collaborators may opt to elevate significant or controversial
|
||||
modifications, or modifications that have not found consensus to the
|
||||
WG for discussion by assigning the ***WG-agenda*** tag to a pull
|
||||
request or issue. The WG should serve as the final arbiter where
|
||||
required.
|
||||
|
||||
For the current list of Collaborators, see the project
|
||||
[README.md](./README.md#members).
|
||||
|
||||
### WG Membership
|
||||
|
||||
WG seats are not time-limited. There is no fixed size of the WG.
|
||||
However, the expected target is between 6 and 12, to ensure adequate
|
||||
coverage of important areas of expertise, balanced with the ability to
|
||||
make decisions efficiently.
|
||||
|
||||
There is no specific set of requirements or qualifications for WG
|
||||
membership beyond these rules.
|
||||
|
||||
The WG may add additional members to the WG by unanimous consensus.
|
||||
|
||||
A WG member may be removed from the WG by voluntary resignation, or by
|
||||
unanimous consensus of all other WG members.
|
||||
|
||||
Changes to WG membership should be posted in the agenda, and may be
|
||||
suggested as any other agenda item (see "WG Meetings" below).
|
||||
|
||||
If an addition or removal is proposed during a meeting, and the full
|
||||
WG is not in attendance to participate, then the addition or removal
|
||||
is added to the agenda for the subsequent meeting. This is to ensure
|
||||
that all members are given the opportunity to participate in all
|
||||
membership decisions. If a WG member is unable to attend a meeting
|
||||
where a planned membership decision is being made, then their consent
|
||||
is assumed.
|
||||
|
||||
No more than 1/3 of the WG members may be affiliated with the same
|
||||
employer. If removal or resignation of a WG member, or a change of
|
||||
employment by a WG member, creates a situation where more than 1/3 of
|
||||
the WG membership shares an employer, then the situation must be
|
||||
immediately remedied by the resignation or removal of one or more WG
|
||||
members affiliated with the over-represented employer(s).
|
||||
|
||||
### WG Meetings
|
||||
|
||||
The WG meets occasionally on a Google Hangout On Air. A designated moderator
|
||||
approved by the WG runs the meeting. Each meeting should be
|
||||
published to YouTube.
|
||||
|
||||
Items are added to the WG agenda that are considered contentious or
|
||||
are modifications of governance, contribution policy, WG membership,
|
||||
or release process.
|
||||
|
||||
The intention of the agenda is not to approve or review all patches;
|
||||
that should happen continuously on GitHub and be handled by the larger
|
||||
group of Collaborators.
|
||||
|
||||
Any community member or contributor can ask that something be added to
|
||||
the next meeting's agenda by logging a GitHub Issue. Any Collaborator,
|
||||
WG member or the moderator can add the item to the agenda by adding
|
||||
the ***WG-agenda*** tag to the issue.
|
||||
|
||||
Prior to each WG meeting the moderator will share the Agenda with
|
||||
members of the WG. WG members can add any items they like to the
|
||||
agenda at the beginning of each meeting. The moderator and the WG
|
||||
cannot veto or remove items.
|
||||
|
||||
The WG may invite persons or representatives from certain projects to
|
||||
participate in a non-voting capacity.
|
||||
|
||||
The moderator is responsible for summarizing the discussion of each
|
||||
agenda item and sends it as a pull request after the meeting.
|
||||
|
||||
### Consensus Seeking Process
|
||||
|
||||
The WG follows a
|
||||
[Consensus
|
||||
Seeking](http://en.wikipedia.org/wiki/Consensus-seeking_decision-making)
|
||||
decision-making model.
|
||||
|
||||
When an agenda item has appeared to reach a consensus the moderator
|
||||
will ask "Does anyone object?" as a final call for dissent from the
|
||||
consensus.
|
||||
|
||||
If an agenda item cannot reach a consensus a WG member can call for
|
||||
either a closing vote or a vote to table the issue to the next
|
||||
meeting. The call for a vote must be seconded by a majority of the WG
|
||||
or else the discussion will continue. Simple majority wins.
|
||||
|
||||
Note that changes to WG membership require a majority consensus. See
|
||||
"WG Membership" above.
|
||||
47
node_modules/readdirp/node_modules/readable-stream/LICENSE
generated
vendored
Normal file
47
node_modules/readdirp/node_modules/readable-stream/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,47 @@
|
||||
Node.js is licensed for use as follows:
|
||||
|
||||
"""
|
||||
Copyright Node.js contributors. All rights reserved.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to
|
||||
deal in the Software without restriction, including without limitation the
|
||||
rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
sell copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
IN THE SOFTWARE.
|
||||
"""
|
||||
|
||||
This license applies to parts of Node.js originating from the
|
||||
https://github.com/joyent/node repository:
|
||||
|
||||
"""
|
||||
Copyright Joyent, Inc. and other Node contributors. All rights reserved.
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to
|
||||
deal in the Software without restriction, including without limitation the
|
||||
rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
sell copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
IN THE SOFTWARE.
|
||||
"""
|
||||
57
node_modules/readdirp/node_modules/readable-stream/README.md
generated
vendored
Normal file
57
node_modules/readdirp/node_modules/readable-stream/README.md
generated
vendored
Normal file
@@ -0,0 +1,57 @@
|
||||
# readable-stream
|
||||
|
||||
***Node-core v7.0.0 streams for userland*** [](https://travis-ci.org/nodejs/readable-stream)
|
||||
|
||||
|
||||
[](https://nodei.co/npm/readable-stream/)
|
||||
[](https://nodei.co/npm/readable-stream/)
|
||||
|
||||
|
||||
[](https://saucelabs.com/u/readable-stream)
|
||||
|
||||
```bash
|
||||
npm install --save readable-stream
|
||||
```
|
||||
|
||||
***Node-core streams for userland***
|
||||
|
||||
This package is a mirror of the Streams2 and Streams3 implementations in
|
||||
Node-core.
|
||||
|
||||
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v7.8.0/docs/api/).
|
||||
|
||||
If you want to guarantee a stable streams base, regardless of what version of
|
||||
Node you, or the users of your libraries are using, use **readable-stream** *only* and avoid the *"stream"* module in Node-core, for background see [this blogpost](http://r.va.gg/2014/06/why-i-dont-use-nodes-core-stream-module.html).
|
||||
|
||||
As of version 2.0.0 **readable-stream** uses semantic versioning.
|
||||
|
||||
# Streams Working Group
|
||||
|
||||
`readable-stream` is maintained by the Streams Working Group, which
|
||||
oversees the development and maintenance of the Streams API within
|
||||
Node.js. The responsibilities of the Streams Working Group include:
|
||||
|
||||
* Addressing stream issues on the Node.js issue tracker.
|
||||
* Authoring and editing stream documentation within the Node.js project.
|
||||
* Reviewing changes to stream subclasses within the Node.js project.
|
||||
* Redirecting changes to streams from the Node.js project to this
|
||||
project.
|
||||
* Assisting in the implementation of stream providers within Node.js.
|
||||
* Recommending versions of `readable-stream` to be included in Node.js.
|
||||
* Messaging about the future of streams to give the community advance
|
||||
notice of changes.
|
||||
|
||||
<a name="members"></a>
|
||||
## Team Members
|
||||
|
||||
* **Chris Dickinson** ([@chrisdickinson](https://github.com/chrisdickinson)) <christopher.s.dickinson@gmail.com>
|
||||
- Release GPG key: 9554F04D7259F04124DE6B476D5A82AC7E37093B
|
||||
* **Calvin Metcalf** ([@calvinmetcalf](https://github.com/calvinmetcalf)) <calvin.metcalf@gmail.com>
|
||||
- Release GPG key: F3EF5F62A87FC27A22E643F714CE4FF5015AA242
|
||||
* **Rod Vagg** ([@rvagg](https://github.com/rvagg)) <rod@vagg.org>
|
||||
- Release GPG key: DD8F2338BAE7501E3DD5AC78C273792F7D83545D
|
||||
* **Sam Newman** ([@sonewman](https://github.com/sonewman)) <newmansam@outlook.com>
|
||||
* **Mathias Buus** ([@mafintosh](https://github.com/mafintosh)) <mathiasbuus@gmail.com>
|
||||
* **Domenic Denicola** ([@domenic](https://github.com/domenic)) <d@domenic.me>
|
||||
* **Matteo Collina** ([@mcollina](https://github.com/mcollina)) <matteo.collina@gmail.com>
|
||||
- Release GPG key: 3ABC01543F22DD2239285CDD818674489FBC127E
|
||||
60
node_modules/readdirp/node_modules/readable-stream/doc/wg-meetings/2015-01-30.md
generated
vendored
Normal file
60
node_modules/readdirp/node_modules/readable-stream/doc/wg-meetings/2015-01-30.md
generated
vendored
Normal file
@@ -0,0 +1,60 @@
|
||||
# streams WG Meeting 2015-01-30
|
||||
|
||||
## Links
|
||||
|
||||
* **Google Hangouts Video**: http://www.youtube.com/watch?v=I9nDOSGfwZg
|
||||
* **GitHub Issue**: https://github.com/iojs/readable-stream/issues/106
|
||||
* **Original Minutes Google Doc**: https://docs.google.com/document/d/17aTgLnjMXIrfjgNaTUnHQO7m3xgzHR2VXBTmi03Qii4/
|
||||
|
||||
## Agenda
|
||||
|
||||
Extracted from https://github.com/iojs/readable-stream/labels/wg-agenda prior to meeting.
|
||||
|
||||
* adopt a charter [#105](https://github.com/iojs/readable-stream/issues/105)
|
||||
* release and versioning strategy [#101](https://github.com/iojs/readable-stream/issues/101)
|
||||
* simpler stream creation [#102](https://github.com/iojs/readable-stream/issues/102)
|
||||
* proposal: deprecate implicit flowing of streams [#99](https://github.com/iojs/readable-stream/issues/99)
|
||||
|
||||
## Minutes
|
||||
|
||||
### adopt a charter
|
||||
|
||||
* group: +1's all around
|
||||
|
||||
### What versioning scheme should be adopted?
|
||||
* group: +1’s 3.0.0
|
||||
* domenic+group: pulling in patches from other sources where appropriate
|
||||
* mikeal: version independently, suggesting versions for io.js
|
||||
* mikeal+domenic: work with TC to notify in advance of changes
|
||||
simpler stream creation
|
||||
|
||||
### streamline creation of streams
|
||||
* sam: streamline creation of streams
|
||||
* domenic: nice simple solution posted
|
||||
but, we lose the opportunity to change the model
|
||||
may not be backwards incompatible (double check keys)
|
||||
|
||||
**action item:** domenic will check
|
||||
|
||||
### remove implicit flowing of streams on(‘data’)
|
||||
* add isFlowing / isPaused
|
||||
* mikeal: worrying that we’re documenting polyfill methods – confuses users
|
||||
* domenic: more reflective API is probably good, with warning labels for users
|
||||
* new section for mad scientists (reflective stream access)
|
||||
* calvin: name the “third state”
|
||||
* mikeal: maybe borrow the name from whatwg?
|
||||
* domenic: we’re missing the “third state”
|
||||
* consensus: kind of difficult to name the third state
|
||||
* mikeal: figure out differences in states / compat
|
||||
* mathias: always flow on data – eliminates third state
|
||||
* explore what it breaks
|
||||
|
||||
**action items:**
|
||||
* ask isaac for ability to list packages by what public io.js APIs they use (esp. Stream)
|
||||
* ask rod/build for infrastructure
|
||||
* **chris**: explore the “flow on data” approach
|
||||
* add isPaused/isFlowing
|
||||
* add new docs section
|
||||
* move isPaused to that section
|
||||
|
||||
|
||||
1
node_modules/readdirp/node_modules/readable-stream/duplex-browser.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/duplex-browser.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('./lib/_stream_duplex.js');
|
||||
1
node_modules/readdirp/node_modules/readable-stream/duplex.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/duplex.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('./readable').Duplex
|
||||
75
node_modules/readdirp/node_modules/readable-stream/lib/_stream_duplex.js
generated
vendored
Normal file
75
node_modules/readdirp/node_modules/readable-stream/lib/_stream_duplex.js
generated
vendored
Normal file
@@ -0,0 +1,75 @@
|
||||
// a duplex stream is just a stream that is both readable and writable.
|
||||
// Since JS doesn't have multiple prototypal inheritance, this class
|
||||
// prototypally inherits from Readable, and then parasitically from
|
||||
// Writable.
|
||||
|
||||
'use strict';
|
||||
|
||||
/*<replacement>*/
|
||||
|
||||
var objectKeys = Object.keys || function (obj) {
|
||||
var keys = [];
|
||||
for (var key in obj) {
|
||||
keys.push(key);
|
||||
}return keys;
|
||||
};
|
||||
/*</replacement>*/
|
||||
|
||||
module.exports = Duplex;
|
||||
|
||||
/*<replacement>*/
|
||||
var processNextTick = require('process-nextick-args');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var util = require('core-util-is');
|
||||
util.inherits = require('inherits');
|
||||
/*</replacement>*/
|
||||
|
||||
var Readable = require('./_stream_readable');
|
||||
var Writable = require('./_stream_writable');
|
||||
|
||||
util.inherits(Duplex, Readable);
|
||||
|
||||
var keys = objectKeys(Writable.prototype);
|
||||
for (var v = 0; v < keys.length; v++) {
|
||||
var method = keys[v];
|
||||
if (!Duplex.prototype[method]) Duplex.prototype[method] = Writable.prototype[method];
|
||||
}
|
||||
|
||||
function Duplex(options) {
|
||||
if (!(this instanceof Duplex)) return new Duplex(options);
|
||||
|
||||
Readable.call(this, options);
|
||||
Writable.call(this, options);
|
||||
|
||||
if (options && options.readable === false) this.readable = false;
|
||||
|
||||
if (options && options.writable === false) this.writable = false;
|
||||
|
||||
this.allowHalfOpen = true;
|
||||
if (options && options.allowHalfOpen === false) this.allowHalfOpen = false;
|
||||
|
||||
this.once('end', onend);
|
||||
}
|
||||
|
||||
// the no-half-open enforcer
|
||||
function onend() {
|
||||
// if we allow half-open state, or if the writable side ended,
|
||||
// then we're ok.
|
||||
if (this.allowHalfOpen || this._writableState.ended) return;
|
||||
|
||||
// no more data can be written.
|
||||
// But allow more writes to happen in this tick.
|
||||
processNextTick(onEndNT, this);
|
||||
}
|
||||
|
||||
function onEndNT(self) {
|
||||
self.end();
|
||||
}
|
||||
|
||||
function forEach(xs, f) {
|
||||
for (var i = 0, l = xs.length; i < l; i++) {
|
||||
f(xs[i], i);
|
||||
}
|
||||
}
|
||||
26
node_modules/readdirp/node_modules/readable-stream/lib/_stream_passthrough.js
generated
vendored
Normal file
26
node_modules/readdirp/node_modules/readable-stream/lib/_stream_passthrough.js
generated
vendored
Normal file
@@ -0,0 +1,26 @@
|
||||
// a passthrough stream.
|
||||
// basically just the most minimal sort of Transform stream.
|
||||
// Every written chunk gets output as-is.
|
||||
|
||||
'use strict';
|
||||
|
||||
module.exports = PassThrough;
|
||||
|
||||
var Transform = require('./_stream_transform');
|
||||
|
||||
/*<replacement>*/
|
||||
var util = require('core-util-is');
|
||||
util.inherits = require('inherits');
|
||||
/*</replacement>*/
|
||||
|
||||
util.inherits(PassThrough, Transform);
|
||||
|
||||
function PassThrough(options) {
|
||||
if (!(this instanceof PassThrough)) return new PassThrough(options);
|
||||
|
||||
Transform.call(this, options);
|
||||
}
|
||||
|
||||
PassThrough.prototype._transform = function (chunk, encoding, cb) {
|
||||
cb(null, chunk);
|
||||
};
|
||||
935
node_modules/readdirp/node_modules/readable-stream/lib/_stream_readable.js
generated
vendored
Normal file
935
node_modules/readdirp/node_modules/readable-stream/lib/_stream_readable.js
generated
vendored
Normal file
@@ -0,0 +1,935 @@
|
||||
'use strict';
|
||||
|
||||
module.exports = Readable;
|
||||
|
||||
/*<replacement>*/
|
||||
var processNextTick = require('process-nextick-args');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var isArray = require('isarray');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var Duplex;
|
||||
/*</replacement>*/
|
||||
|
||||
Readable.ReadableState = ReadableState;
|
||||
|
||||
/*<replacement>*/
|
||||
var EE = require('events').EventEmitter;
|
||||
|
||||
var EElistenerCount = function (emitter, type) {
|
||||
return emitter.listeners(type).length;
|
||||
};
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var Stream = require('./internal/streams/stream');
|
||||
/*</replacement>*/
|
||||
|
||||
var Buffer = require('buffer').Buffer;
|
||||
/*<replacement>*/
|
||||
var bufferShim = require('buffer-shims');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var util = require('core-util-is');
|
||||
util.inherits = require('inherits');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var debugUtil = require('util');
|
||||
var debug = void 0;
|
||||
if (debugUtil && debugUtil.debuglog) {
|
||||
debug = debugUtil.debuglog('stream');
|
||||
} else {
|
||||
debug = function () {};
|
||||
}
|
||||
/*</replacement>*/
|
||||
|
||||
var BufferList = require('./internal/streams/BufferList');
|
||||
var StringDecoder;
|
||||
|
||||
util.inherits(Readable, Stream);
|
||||
|
||||
var kProxyEvents = ['error', 'close', 'destroy', 'pause', 'resume'];
|
||||
|
||||
function prependListener(emitter, event, fn) {
|
||||
// Sadly this is not cacheable as some libraries bundle their own
|
||||
// event emitter implementation with them.
|
||||
if (typeof emitter.prependListener === 'function') {
|
||||
return emitter.prependListener(event, fn);
|
||||
} else {
|
||||
// This is a hack to make sure that our error handler is attached before any
|
||||
// userland ones. NEVER DO THIS. This is here only because this code needs
|
||||
// to continue to work with older versions of Node.js that do not include
|
||||
// the prependListener() method. The goal is to eventually remove this hack.
|
||||
if (!emitter._events || !emitter._events[event]) emitter.on(event, fn);else if (isArray(emitter._events[event])) emitter._events[event].unshift(fn);else emitter._events[event] = [fn, emitter._events[event]];
|
||||
}
|
||||
}
|
||||
|
||||
function ReadableState(options, stream) {
|
||||
Duplex = Duplex || require('./_stream_duplex');
|
||||
|
||||
options = options || {};
|
||||
|
||||
// object stream flag. Used to make read(n) ignore n and to
|
||||
// make all the buffer merging and length checks go away
|
||||
this.objectMode = !!options.objectMode;
|
||||
|
||||
if (stream instanceof Duplex) this.objectMode = this.objectMode || !!options.readableObjectMode;
|
||||
|
||||
// the point at which it stops calling _read() to fill the buffer
|
||||
// Note: 0 is a valid value, means "don't call _read preemptively ever"
|
||||
var hwm = options.highWaterMark;
|
||||
var defaultHwm = this.objectMode ? 16 : 16 * 1024;
|
||||
this.highWaterMark = hwm || hwm === 0 ? hwm : defaultHwm;
|
||||
|
||||
// cast to ints.
|
||||
this.highWaterMark = ~~this.highWaterMark;
|
||||
|
||||
// A linked list is used to store data chunks instead of an array because the
|
||||
// linked list can remove elements from the beginning faster than
|
||||
// array.shift()
|
||||
this.buffer = new BufferList();
|
||||
this.length = 0;
|
||||
this.pipes = null;
|
||||
this.pipesCount = 0;
|
||||
this.flowing = null;
|
||||
this.ended = false;
|
||||
this.endEmitted = false;
|
||||
this.reading = false;
|
||||
|
||||
// a flag to be able to tell if the onwrite cb is called immediately,
|
||||
// or on a later tick. We set this to true at first, because any
|
||||
// actions that shouldn't happen until "later" should generally also
|
||||
// not happen before the first write call.
|
||||
this.sync = true;
|
||||
|
||||
// whenever we return null, then we set a flag to say
|
||||
// that we're awaiting a 'readable' event emission.
|
||||
this.needReadable = false;
|
||||
this.emittedReadable = false;
|
||||
this.readableListening = false;
|
||||
this.resumeScheduled = false;
|
||||
|
||||
// Crypto is kind of old and crusty. Historically, its default string
|
||||
// encoding is 'binary' so we have to make this configurable.
|
||||
// Everything else in the universe uses 'utf8', though.
|
||||
this.defaultEncoding = options.defaultEncoding || 'utf8';
|
||||
|
||||
// when piping, we only care about 'readable' events that happen
|
||||
// after read()ing all the bytes and not getting any pushback.
|
||||
this.ranOut = false;
|
||||
|
||||
// the number of writers that are awaiting a drain event in .pipe()s
|
||||
this.awaitDrain = 0;
|
||||
|
||||
// if true, a maybeReadMore has been scheduled
|
||||
this.readingMore = false;
|
||||
|
||||
this.decoder = null;
|
||||
this.encoding = null;
|
||||
if (options.encoding) {
|
||||
if (!StringDecoder) StringDecoder = require('string_decoder/').StringDecoder;
|
||||
this.decoder = new StringDecoder(options.encoding);
|
||||
this.encoding = options.encoding;
|
||||
}
|
||||
}
|
||||
|
||||
function Readable(options) {
|
||||
Duplex = Duplex || require('./_stream_duplex');
|
||||
|
||||
if (!(this instanceof Readable)) return new Readable(options);
|
||||
|
||||
this._readableState = new ReadableState(options, this);
|
||||
|
||||
// legacy
|
||||
this.readable = true;
|
||||
|
||||
if (options && typeof options.read === 'function') this._read = options.read;
|
||||
|
||||
Stream.call(this);
|
||||
}
|
||||
|
||||
// Manually shove something into the read() buffer.
|
||||
// This returns true if the highWaterMark has not been hit yet,
|
||||
// similar to how Writable.write() returns true if you should
|
||||
// write() some more.
|
||||
Readable.prototype.push = function (chunk, encoding) {
|
||||
var state = this._readableState;
|
||||
|
||||
if (!state.objectMode && typeof chunk === 'string') {
|
||||
encoding = encoding || state.defaultEncoding;
|
||||
if (encoding !== state.encoding) {
|
||||
chunk = bufferShim.from(chunk, encoding);
|
||||
encoding = '';
|
||||
}
|
||||
}
|
||||
|
||||
return readableAddChunk(this, state, chunk, encoding, false);
|
||||
};
|
||||
|
||||
// Unshift should *always* be something directly out of read()
|
||||
Readable.prototype.unshift = function (chunk) {
|
||||
var state = this._readableState;
|
||||
return readableAddChunk(this, state, chunk, '', true);
|
||||
};
|
||||
|
||||
Readable.prototype.isPaused = function () {
|
||||
return this._readableState.flowing === false;
|
||||
};
|
||||
|
||||
function readableAddChunk(stream, state, chunk, encoding, addToFront) {
|
||||
var er = chunkInvalid(state, chunk);
|
||||
if (er) {
|
||||
stream.emit('error', er);
|
||||
} else if (chunk === null) {
|
||||
state.reading = false;
|
||||
onEofChunk(stream, state);
|
||||
} else if (state.objectMode || chunk && chunk.length > 0) {
|
||||
if (state.ended && !addToFront) {
|
||||
var e = new Error('stream.push() after EOF');
|
||||
stream.emit('error', e);
|
||||
} else if (state.endEmitted && addToFront) {
|
||||
var _e = new Error('stream.unshift() after end event');
|
||||
stream.emit('error', _e);
|
||||
} else {
|
||||
var skipAdd;
|
||||
if (state.decoder && !addToFront && !encoding) {
|
||||
chunk = state.decoder.write(chunk);
|
||||
skipAdd = !state.objectMode && chunk.length === 0;
|
||||
}
|
||||
|
||||
if (!addToFront) state.reading = false;
|
||||
|
||||
// Don't add to the buffer if we've decoded to an empty string chunk and
|
||||
// we're not in object mode
|
||||
if (!skipAdd) {
|
||||
// if we want the data now, just emit it.
|
||||
if (state.flowing && state.length === 0 && !state.sync) {
|
||||
stream.emit('data', chunk);
|
||||
stream.read(0);
|
||||
} else {
|
||||
// update the buffer info.
|
||||
state.length += state.objectMode ? 1 : chunk.length;
|
||||
if (addToFront) state.buffer.unshift(chunk);else state.buffer.push(chunk);
|
||||
|
||||
if (state.needReadable) emitReadable(stream);
|
||||
}
|
||||
}
|
||||
|
||||
maybeReadMore(stream, state);
|
||||
}
|
||||
} else if (!addToFront) {
|
||||
state.reading = false;
|
||||
}
|
||||
|
||||
return needMoreData(state);
|
||||
}
|
||||
|
||||
// if it's past the high water mark, we can push in some more.
|
||||
// Also, if we have no data yet, we can stand some
|
||||
// more bytes. This is to work around cases where hwm=0,
|
||||
// such as the repl. Also, if the push() triggered a
|
||||
// readable event, and the user called read(largeNumber) such that
|
||||
// needReadable was set, then we ought to push more, so that another
|
||||
// 'readable' event will be triggered.
|
||||
function needMoreData(state) {
|
||||
return !state.ended && (state.needReadable || state.length < state.highWaterMark || state.length === 0);
|
||||
}
|
||||
|
||||
// backwards compatibility.
|
||||
Readable.prototype.setEncoding = function (enc) {
|
||||
if (!StringDecoder) StringDecoder = require('string_decoder/').StringDecoder;
|
||||
this._readableState.decoder = new StringDecoder(enc);
|
||||
this._readableState.encoding = enc;
|
||||
return this;
|
||||
};
|
||||
|
||||
// Don't raise the hwm > 8MB
|
||||
var MAX_HWM = 0x800000;
|
||||
function computeNewHighWaterMark(n) {
|
||||
if (n >= MAX_HWM) {
|
||||
n = MAX_HWM;
|
||||
} else {
|
||||
// Get the next highest power of 2 to prevent increasing hwm excessively in
|
||||
// tiny amounts
|
||||
n--;
|
||||
n |= n >>> 1;
|
||||
n |= n >>> 2;
|
||||
n |= n >>> 4;
|
||||
n |= n >>> 8;
|
||||
n |= n >>> 16;
|
||||
n++;
|
||||
}
|
||||
return n;
|
||||
}
|
||||
|
||||
// This function is designed to be inlinable, so please take care when making
|
||||
// changes to the function body.
|
||||
function howMuchToRead(n, state) {
|
||||
if (n <= 0 || state.length === 0 && state.ended) return 0;
|
||||
if (state.objectMode) return 1;
|
||||
if (n !== n) {
|
||||
// Only flow one buffer at a time
|
||||
if (state.flowing && state.length) return state.buffer.head.data.length;else return state.length;
|
||||
}
|
||||
// If we're asking for more than the current hwm, then raise the hwm.
|
||||
if (n > state.highWaterMark) state.highWaterMark = computeNewHighWaterMark(n);
|
||||
if (n <= state.length) return n;
|
||||
// Don't have enough
|
||||
if (!state.ended) {
|
||||
state.needReadable = true;
|
||||
return 0;
|
||||
}
|
||||
return state.length;
|
||||
}
|
||||
|
||||
// you can override either this method, or the async _read(n) below.
|
||||
Readable.prototype.read = function (n) {
|
||||
debug('read', n);
|
||||
n = parseInt(n, 10);
|
||||
var state = this._readableState;
|
||||
var nOrig = n;
|
||||
|
||||
if (n !== 0) state.emittedReadable = false;
|
||||
|
||||
// if we're doing read(0) to trigger a readable event, but we
|
||||
// already have a bunch of data in the buffer, then just trigger
|
||||
// the 'readable' event and move on.
|
||||
if (n === 0 && state.needReadable && (state.length >= state.highWaterMark || state.ended)) {
|
||||
debug('read: emitReadable', state.length, state.ended);
|
||||
if (state.length === 0 && state.ended) endReadable(this);else emitReadable(this);
|
||||
return null;
|
||||
}
|
||||
|
||||
n = howMuchToRead(n, state);
|
||||
|
||||
// if we've ended, and we're now clear, then finish it up.
|
||||
if (n === 0 && state.ended) {
|
||||
if (state.length === 0) endReadable(this);
|
||||
return null;
|
||||
}
|
||||
|
||||
// All the actual chunk generation logic needs to be
|
||||
// *below* the call to _read. The reason is that in certain
|
||||
// synthetic stream cases, such as passthrough streams, _read
|
||||
// may be a completely synchronous operation which may change
|
||||
// the state of the read buffer, providing enough data when
|
||||
// before there was *not* enough.
|
||||
//
|
||||
// So, the steps are:
|
||||
// 1. Figure out what the state of things will be after we do
|
||||
// a read from the buffer.
|
||||
//
|
||||
// 2. If that resulting state will trigger a _read, then call _read.
|
||||
// Note that this may be asynchronous, or synchronous. Yes, it is
|
||||
// deeply ugly to write APIs this way, but that still doesn't mean
|
||||
// that the Readable class should behave improperly, as streams are
|
||||
// designed to be sync/async agnostic.
|
||||
// Take note if the _read call is sync or async (ie, if the read call
|
||||
// has returned yet), so that we know whether or not it's safe to emit
|
||||
// 'readable' etc.
|
||||
//
|
||||
// 3. Actually pull the requested chunks out of the buffer and return.
|
||||
|
||||
// if we need a readable event, then we need to do some reading.
|
||||
var doRead = state.needReadable;
|
||||
debug('need readable', doRead);
|
||||
|
||||
// if we currently have less than the highWaterMark, then also read some
|
||||
if (state.length === 0 || state.length - n < state.highWaterMark) {
|
||||
doRead = true;
|
||||
debug('length less than watermark', doRead);
|
||||
}
|
||||
|
||||
// however, if we've ended, then there's no point, and if we're already
|
||||
// reading, then it's unnecessary.
|
||||
if (state.ended || state.reading) {
|
||||
doRead = false;
|
||||
debug('reading or ended', doRead);
|
||||
} else if (doRead) {
|
||||
debug('do read');
|
||||
state.reading = true;
|
||||
state.sync = true;
|
||||
// if the length is currently zero, then we *need* a readable event.
|
||||
if (state.length === 0) state.needReadable = true;
|
||||
// call internal read method
|
||||
this._read(state.highWaterMark);
|
||||
state.sync = false;
|
||||
// If _read pushed data synchronously, then `reading` will be false,
|
||||
// and we need to re-evaluate how much data we can return to the user.
|
||||
if (!state.reading) n = howMuchToRead(nOrig, state);
|
||||
}
|
||||
|
||||
var ret;
|
||||
if (n > 0) ret = fromList(n, state);else ret = null;
|
||||
|
||||
if (ret === null) {
|
||||
state.needReadable = true;
|
||||
n = 0;
|
||||
} else {
|
||||
state.length -= n;
|
||||
}
|
||||
|
||||
if (state.length === 0) {
|
||||
// If we have nothing in the buffer, then we want to know
|
||||
// as soon as we *do* get something into the buffer.
|
||||
if (!state.ended) state.needReadable = true;
|
||||
|
||||
// If we tried to read() past the EOF, then emit end on the next tick.
|
||||
if (nOrig !== n && state.ended) endReadable(this);
|
||||
}
|
||||
|
||||
if (ret !== null) this.emit('data', ret);
|
||||
|
||||
return ret;
|
||||
};
|
||||
|
||||
function chunkInvalid(state, chunk) {
|
||||
var er = null;
|
||||
if (!Buffer.isBuffer(chunk) && typeof chunk !== 'string' && chunk !== null && chunk !== undefined && !state.objectMode) {
|
||||
er = new TypeError('Invalid non-string/buffer chunk');
|
||||
}
|
||||
return er;
|
||||
}
|
||||
|
||||
function onEofChunk(stream, state) {
|
||||
if (state.ended) return;
|
||||
if (state.decoder) {
|
||||
var chunk = state.decoder.end();
|
||||
if (chunk && chunk.length) {
|
||||
state.buffer.push(chunk);
|
||||
state.length += state.objectMode ? 1 : chunk.length;
|
||||
}
|
||||
}
|
||||
state.ended = true;
|
||||
|
||||
// emit 'readable' now to make sure it gets picked up.
|
||||
emitReadable(stream);
|
||||
}
|
||||
|
||||
// Don't emit readable right away in sync mode, because this can trigger
|
||||
// another read() call => stack overflow. This way, it might trigger
|
||||
// a nextTick recursion warning, but that's not so bad.
|
||||
function emitReadable(stream) {
|
||||
var state = stream._readableState;
|
||||
state.needReadable = false;
|
||||
if (!state.emittedReadable) {
|
||||
debug('emitReadable', state.flowing);
|
||||
state.emittedReadable = true;
|
||||
if (state.sync) processNextTick(emitReadable_, stream);else emitReadable_(stream);
|
||||
}
|
||||
}
|
||||
|
||||
function emitReadable_(stream) {
|
||||
debug('emit readable');
|
||||
stream.emit('readable');
|
||||
flow(stream);
|
||||
}
|
||||
|
||||
// at this point, the user has presumably seen the 'readable' event,
|
||||
// and called read() to consume some data. that may have triggered
|
||||
// in turn another _read(n) call, in which case reading = true if
|
||||
// it's in progress.
|
||||
// However, if we're not ended, or reading, and the length < hwm,
|
||||
// then go ahead and try to read some more preemptively.
|
||||
function maybeReadMore(stream, state) {
|
||||
if (!state.readingMore) {
|
||||
state.readingMore = true;
|
||||
processNextTick(maybeReadMore_, stream, state);
|
||||
}
|
||||
}
|
||||
|
||||
function maybeReadMore_(stream, state) {
|
||||
var len = state.length;
|
||||
while (!state.reading && !state.flowing && !state.ended && state.length < state.highWaterMark) {
|
||||
debug('maybeReadMore read 0');
|
||||
stream.read(0);
|
||||
if (len === state.length)
|
||||
// didn't get any data, stop spinning.
|
||||
break;else len = state.length;
|
||||
}
|
||||
state.readingMore = false;
|
||||
}
|
||||
|
||||
// abstract method. to be overridden in specific implementation classes.
|
||||
// call cb(er, data) where data is <= n in length.
|
||||
// for virtual (non-string, non-buffer) streams, "length" is somewhat
|
||||
// arbitrary, and perhaps not very meaningful.
|
||||
Readable.prototype._read = function (n) {
|
||||
this.emit('error', new Error('_read() is not implemented'));
|
||||
};
|
||||
|
||||
Readable.prototype.pipe = function (dest, pipeOpts) {
|
||||
var src = this;
|
||||
var state = this._readableState;
|
||||
|
||||
switch (state.pipesCount) {
|
||||
case 0:
|
||||
state.pipes = dest;
|
||||
break;
|
||||
case 1:
|
||||
state.pipes = [state.pipes, dest];
|
||||
break;
|
||||
default:
|
||||
state.pipes.push(dest);
|
||||
break;
|
||||
}
|
||||
state.pipesCount += 1;
|
||||
debug('pipe count=%d opts=%j', state.pipesCount, pipeOpts);
|
||||
|
||||
var doEnd = (!pipeOpts || pipeOpts.end !== false) && dest !== process.stdout && dest !== process.stderr;
|
||||
|
||||
var endFn = doEnd ? onend : cleanup;
|
||||
if (state.endEmitted) processNextTick(endFn);else src.once('end', endFn);
|
||||
|
||||
dest.on('unpipe', onunpipe);
|
||||
function onunpipe(readable) {
|
||||
debug('onunpipe');
|
||||
if (readable === src) {
|
||||
cleanup();
|
||||
}
|
||||
}
|
||||
|
||||
function onend() {
|
||||
debug('onend');
|
||||
dest.end();
|
||||
}
|
||||
|
||||
// when the dest drains, it reduces the awaitDrain counter
|
||||
// on the source. This would be more elegant with a .once()
|
||||
// handler in flow(), but adding and removing repeatedly is
|
||||
// too slow.
|
||||
var ondrain = pipeOnDrain(src);
|
||||
dest.on('drain', ondrain);
|
||||
|
||||
var cleanedUp = false;
|
||||
function cleanup() {
|
||||
debug('cleanup');
|
||||
// cleanup event handlers once the pipe is broken
|
||||
dest.removeListener('close', onclose);
|
||||
dest.removeListener('finish', onfinish);
|
||||
dest.removeListener('drain', ondrain);
|
||||
dest.removeListener('error', onerror);
|
||||
dest.removeListener('unpipe', onunpipe);
|
||||
src.removeListener('end', onend);
|
||||
src.removeListener('end', cleanup);
|
||||
src.removeListener('data', ondata);
|
||||
|
||||
cleanedUp = true;
|
||||
|
||||
// if the reader is waiting for a drain event from this
|
||||
// specific writer, then it would cause it to never start
|
||||
// flowing again.
|
||||
// So, if this is awaiting a drain, then we just call it now.
|
||||
// If we don't know, then assume that we are waiting for one.
|
||||
if (state.awaitDrain && (!dest._writableState || dest._writableState.needDrain)) ondrain();
|
||||
}
|
||||
|
||||
// If the user pushes more data while we're writing to dest then we'll end up
|
||||
// in ondata again. However, we only want to increase awaitDrain once because
|
||||
// dest will only emit one 'drain' event for the multiple writes.
|
||||
// => Introduce a guard on increasing awaitDrain.
|
||||
var increasedAwaitDrain = false;
|
||||
src.on('data', ondata);
|
||||
function ondata(chunk) {
|
||||
debug('ondata');
|
||||
increasedAwaitDrain = false;
|
||||
var ret = dest.write(chunk);
|
||||
if (false === ret && !increasedAwaitDrain) {
|
||||
// If the user unpiped during `dest.write()`, it is possible
|
||||
// to get stuck in a permanently paused state if that write
|
||||
// also returned false.
|
||||
// => Check whether `dest` is still a piping destination.
|
||||
if ((state.pipesCount === 1 && state.pipes === dest || state.pipesCount > 1 && indexOf(state.pipes, dest) !== -1) && !cleanedUp) {
|
||||
debug('false write response, pause', src._readableState.awaitDrain);
|
||||
src._readableState.awaitDrain++;
|
||||
increasedAwaitDrain = true;
|
||||
}
|
||||
src.pause();
|
||||
}
|
||||
}
|
||||
|
||||
// if the dest has an error, then stop piping into it.
|
||||
// however, don't suppress the throwing behavior for this.
|
||||
function onerror(er) {
|
||||
debug('onerror', er);
|
||||
unpipe();
|
||||
dest.removeListener('error', onerror);
|
||||
if (EElistenerCount(dest, 'error') === 0) dest.emit('error', er);
|
||||
}
|
||||
|
||||
// Make sure our error handler is attached before userland ones.
|
||||
prependListener(dest, 'error', onerror);
|
||||
|
||||
// Both close and finish should trigger unpipe, but only once.
|
||||
function onclose() {
|
||||
dest.removeListener('finish', onfinish);
|
||||
unpipe();
|
||||
}
|
||||
dest.once('close', onclose);
|
||||
function onfinish() {
|
||||
debug('onfinish');
|
||||
dest.removeListener('close', onclose);
|
||||
unpipe();
|
||||
}
|
||||
dest.once('finish', onfinish);
|
||||
|
||||
function unpipe() {
|
||||
debug('unpipe');
|
||||
src.unpipe(dest);
|
||||
}
|
||||
|
||||
// tell the dest that it's being piped to
|
||||
dest.emit('pipe', src);
|
||||
|
||||
// start the flow if it hasn't been started already.
|
||||
if (!state.flowing) {
|
||||
debug('pipe resume');
|
||||
src.resume();
|
||||
}
|
||||
|
||||
return dest;
|
||||
};
|
||||
|
||||
function pipeOnDrain(src) {
|
||||
return function () {
|
||||
var state = src._readableState;
|
||||
debug('pipeOnDrain', state.awaitDrain);
|
||||
if (state.awaitDrain) state.awaitDrain--;
|
||||
if (state.awaitDrain === 0 && EElistenerCount(src, 'data')) {
|
||||
state.flowing = true;
|
||||
flow(src);
|
||||
}
|
||||
};
|
||||
}
|
||||
|
||||
Readable.prototype.unpipe = function (dest) {
|
||||
var state = this._readableState;
|
||||
|
||||
// if we're not piping anywhere, then do nothing.
|
||||
if (state.pipesCount === 0) return this;
|
||||
|
||||
// just one destination. most common case.
|
||||
if (state.pipesCount === 1) {
|
||||
// passed in one, but it's not the right one.
|
||||
if (dest && dest !== state.pipes) return this;
|
||||
|
||||
if (!dest) dest = state.pipes;
|
||||
|
||||
// got a match.
|
||||
state.pipes = null;
|
||||
state.pipesCount = 0;
|
||||
state.flowing = false;
|
||||
if (dest) dest.emit('unpipe', this);
|
||||
return this;
|
||||
}
|
||||
|
||||
// slow case. multiple pipe destinations.
|
||||
|
||||
if (!dest) {
|
||||
// remove all.
|
||||
var dests = state.pipes;
|
||||
var len = state.pipesCount;
|
||||
state.pipes = null;
|
||||
state.pipesCount = 0;
|
||||
state.flowing = false;
|
||||
|
||||
for (var i = 0; i < len; i++) {
|
||||
dests[i].emit('unpipe', this);
|
||||
}return this;
|
||||
}
|
||||
|
||||
// try to find the right one.
|
||||
var index = indexOf(state.pipes, dest);
|
||||
if (index === -1) return this;
|
||||
|
||||
state.pipes.splice(index, 1);
|
||||
state.pipesCount -= 1;
|
||||
if (state.pipesCount === 1) state.pipes = state.pipes[0];
|
||||
|
||||
dest.emit('unpipe', this);
|
||||
|
||||
return this;
|
||||
};
|
||||
|
||||
// set up data events if they are asked for
|
||||
// Ensure readable listeners eventually get something
|
||||
Readable.prototype.on = function (ev, fn) {
|
||||
var res = Stream.prototype.on.call(this, ev, fn);
|
||||
|
||||
if (ev === 'data') {
|
||||
// Start flowing on next tick if stream isn't explicitly paused
|
||||
if (this._readableState.flowing !== false) this.resume();
|
||||
} else if (ev === 'readable') {
|
||||
var state = this._readableState;
|
||||
if (!state.endEmitted && !state.readableListening) {
|
||||
state.readableListening = state.needReadable = true;
|
||||
state.emittedReadable = false;
|
||||
if (!state.reading) {
|
||||
processNextTick(nReadingNextTick, this);
|
||||
} else if (state.length) {
|
||||
emitReadable(this, state);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return res;
|
||||
};
|
||||
Readable.prototype.addListener = Readable.prototype.on;
|
||||
|
||||
function nReadingNextTick(self) {
|
||||
debug('readable nexttick read 0');
|
||||
self.read(0);
|
||||
}
|
||||
|
||||
// pause() and resume() are remnants of the legacy readable stream API
|
||||
// If the user uses them, then switch into old mode.
|
||||
Readable.prototype.resume = function () {
|
||||
var state = this._readableState;
|
||||
if (!state.flowing) {
|
||||
debug('resume');
|
||||
state.flowing = true;
|
||||
resume(this, state);
|
||||
}
|
||||
return this;
|
||||
};
|
||||
|
||||
function resume(stream, state) {
|
||||
if (!state.resumeScheduled) {
|
||||
state.resumeScheduled = true;
|
||||
processNextTick(resume_, stream, state);
|
||||
}
|
||||
}
|
||||
|
||||
function resume_(stream, state) {
|
||||
if (!state.reading) {
|
||||
debug('resume read 0');
|
||||
stream.read(0);
|
||||
}
|
||||
|
||||
state.resumeScheduled = false;
|
||||
state.awaitDrain = 0;
|
||||
stream.emit('resume');
|
||||
flow(stream);
|
||||
if (state.flowing && !state.reading) stream.read(0);
|
||||
}
|
||||
|
||||
Readable.prototype.pause = function () {
|
||||
debug('call pause flowing=%j', this._readableState.flowing);
|
||||
if (false !== this._readableState.flowing) {
|
||||
debug('pause');
|
||||
this._readableState.flowing = false;
|
||||
this.emit('pause');
|
||||
}
|
||||
return this;
|
||||
};
|
||||
|
||||
function flow(stream) {
|
||||
var state = stream._readableState;
|
||||
debug('flow', state.flowing);
|
||||
while (state.flowing && stream.read() !== null) {}
|
||||
}
|
||||
|
||||
// wrap an old-style stream as the async data source.
|
||||
// This is *not* part of the readable stream interface.
|
||||
// It is an ugly unfortunate mess of history.
|
||||
Readable.prototype.wrap = function (stream) {
|
||||
var state = this._readableState;
|
||||
var paused = false;
|
||||
|
||||
var self = this;
|
||||
stream.on('end', function () {
|
||||
debug('wrapped end');
|
||||
if (state.decoder && !state.ended) {
|
||||
var chunk = state.decoder.end();
|
||||
if (chunk && chunk.length) self.push(chunk);
|
||||
}
|
||||
|
||||
self.push(null);
|
||||
});
|
||||
|
||||
stream.on('data', function (chunk) {
|
||||
debug('wrapped data');
|
||||
if (state.decoder) chunk = state.decoder.write(chunk);
|
||||
|
||||
// don't skip over falsy values in objectMode
|
||||
if (state.objectMode && (chunk === null || chunk === undefined)) return;else if (!state.objectMode && (!chunk || !chunk.length)) return;
|
||||
|
||||
var ret = self.push(chunk);
|
||||
if (!ret) {
|
||||
paused = true;
|
||||
stream.pause();
|
||||
}
|
||||
});
|
||||
|
||||
// proxy all the other methods.
|
||||
// important when wrapping filters and duplexes.
|
||||
for (var i in stream) {
|
||||
if (this[i] === undefined && typeof stream[i] === 'function') {
|
||||
this[i] = function (method) {
|
||||
return function () {
|
||||
return stream[method].apply(stream, arguments);
|
||||
};
|
||||
}(i);
|
||||
}
|
||||
}
|
||||
|
||||
// proxy certain important events.
|
||||
for (var n = 0; n < kProxyEvents.length; n++) {
|
||||
stream.on(kProxyEvents[n], self.emit.bind(self, kProxyEvents[n]));
|
||||
}
|
||||
|
||||
// when we try to consume some more bytes, simply unpause the
|
||||
// underlying stream.
|
||||
self._read = function (n) {
|
||||
debug('wrapped _read', n);
|
||||
if (paused) {
|
||||
paused = false;
|
||||
stream.resume();
|
||||
}
|
||||
};
|
||||
|
||||
return self;
|
||||
};
|
||||
|
||||
// exposed for testing purposes only.
|
||||
Readable._fromList = fromList;
|
||||
|
||||
// Pluck off n bytes from an array of buffers.
|
||||
// Length is the combined lengths of all the buffers in the list.
|
||||
// This function is designed to be inlinable, so please take care when making
|
||||
// changes to the function body.
|
||||
function fromList(n, state) {
|
||||
// nothing buffered
|
||||
if (state.length === 0) return null;
|
||||
|
||||
var ret;
|
||||
if (state.objectMode) ret = state.buffer.shift();else if (!n || n >= state.length) {
|
||||
// read it all, truncate the list
|
||||
if (state.decoder) ret = state.buffer.join('');else if (state.buffer.length === 1) ret = state.buffer.head.data;else ret = state.buffer.concat(state.length);
|
||||
state.buffer.clear();
|
||||
} else {
|
||||
// read part of list
|
||||
ret = fromListPartial(n, state.buffer, state.decoder);
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
// Extracts only enough buffered data to satisfy the amount requested.
|
||||
// This function is designed to be inlinable, so please take care when making
|
||||
// changes to the function body.
|
||||
function fromListPartial(n, list, hasStrings) {
|
||||
var ret;
|
||||
if (n < list.head.data.length) {
|
||||
// slice is the same for buffers and strings
|
||||
ret = list.head.data.slice(0, n);
|
||||
list.head.data = list.head.data.slice(n);
|
||||
} else if (n === list.head.data.length) {
|
||||
// first chunk is a perfect match
|
||||
ret = list.shift();
|
||||
} else {
|
||||
// result spans more than one buffer
|
||||
ret = hasStrings ? copyFromBufferString(n, list) : copyFromBuffer(n, list);
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
// Copies a specified amount of characters from the list of buffered data
|
||||
// chunks.
|
||||
// This function is designed to be inlinable, so please take care when making
|
||||
// changes to the function body.
|
||||
function copyFromBufferString(n, list) {
|
||||
var p = list.head;
|
||||
var c = 1;
|
||||
var ret = p.data;
|
||||
n -= ret.length;
|
||||
while (p = p.next) {
|
||||
var str = p.data;
|
||||
var nb = n > str.length ? str.length : n;
|
||||
if (nb === str.length) ret += str;else ret += str.slice(0, n);
|
||||
n -= nb;
|
||||
if (n === 0) {
|
||||
if (nb === str.length) {
|
||||
++c;
|
||||
if (p.next) list.head = p.next;else list.head = list.tail = null;
|
||||
} else {
|
||||
list.head = p;
|
||||
p.data = str.slice(nb);
|
||||
}
|
||||
break;
|
||||
}
|
||||
++c;
|
||||
}
|
||||
list.length -= c;
|
||||
return ret;
|
||||
}
|
||||
|
||||
// Copies a specified amount of bytes from the list of buffered data chunks.
|
||||
// This function is designed to be inlinable, so please take care when making
|
||||
// changes to the function body.
|
||||
function copyFromBuffer(n, list) {
|
||||
var ret = bufferShim.allocUnsafe(n);
|
||||
var p = list.head;
|
||||
var c = 1;
|
||||
p.data.copy(ret);
|
||||
n -= p.data.length;
|
||||
while (p = p.next) {
|
||||
var buf = p.data;
|
||||
var nb = n > buf.length ? buf.length : n;
|
||||
buf.copy(ret, ret.length - n, 0, nb);
|
||||
n -= nb;
|
||||
if (n === 0) {
|
||||
if (nb === buf.length) {
|
||||
++c;
|
||||
if (p.next) list.head = p.next;else list.head = list.tail = null;
|
||||
} else {
|
||||
list.head = p;
|
||||
p.data = buf.slice(nb);
|
||||
}
|
||||
break;
|
||||
}
|
||||
++c;
|
||||
}
|
||||
list.length -= c;
|
||||
return ret;
|
||||
}
|
||||
|
||||
function endReadable(stream) {
|
||||
var state = stream._readableState;
|
||||
|
||||
// If we get here before consuming all the bytes, then that is a
|
||||
// bug in node. Should never happen.
|
||||
if (state.length > 0) throw new Error('"endReadable()" called on non-empty stream');
|
||||
|
||||
if (!state.endEmitted) {
|
||||
state.ended = true;
|
||||
processNextTick(endReadableNT, state, stream);
|
||||
}
|
||||
}
|
||||
|
||||
function endReadableNT(state, stream) {
|
||||
// Check that we didn't get one last unshift.
|
||||
if (!state.endEmitted && state.length === 0) {
|
||||
state.endEmitted = true;
|
||||
stream.readable = false;
|
||||
stream.emit('end');
|
||||
}
|
||||
}
|
||||
|
||||
function forEach(xs, f) {
|
||||
for (var i = 0, l = xs.length; i < l; i++) {
|
||||
f(xs[i], i);
|
||||
}
|
||||
}
|
||||
|
||||
function indexOf(xs, x) {
|
||||
for (var i = 0, l = xs.length; i < l; i++) {
|
||||
if (xs[i] === x) return i;
|
||||
}
|
||||
return -1;
|
||||
}
|
||||
182
node_modules/readdirp/node_modules/readable-stream/lib/_stream_transform.js
generated
vendored
Normal file
182
node_modules/readdirp/node_modules/readable-stream/lib/_stream_transform.js
generated
vendored
Normal file
@@ -0,0 +1,182 @@
|
||||
// a transform stream is a readable/writable stream where you do
|
||||
// something with the data. Sometimes it's called a "filter",
|
||||
// but that's not a great name for it, since that implies a thing where
|
||||
// some bits pass through, and others are simply ignored. (That would
|
||||
// be a valid example of a transform, of course.)
|
||||
//
|
||||
// While the output is causally related to the input, it's not a
|
||||
// necessarily symmetric or synchronous transformation. For example,
|
||||
// a zlib stream might take multiple plain-text writes(), and then
|
||||
// emit a single compressed chunk some time in the future.
|
||||
//
|
||||
// Here's how this works:
|
||||
//
|
||||
// The Transform stream has all the aspects of the readable and writable
|
||||
// stream classes. When you write(chunk), that calls _write(chunk,cb)
|
||||
// internally, and returns false if there's a lot of pending writes
|
||||
// buffered up. When you call read(), that calls _read(n) until
|
||||
// there's enough pending readable data buffered up.
|
||||
//
|
||||
// In a transform stream, the written data is placed in a buffer. When
|
||||
// _read(n) is called, it transforms the queued up data, calling the
|
||||
// buffered _write cb's as it consumes chunks. If consuming a single
|
||||
// written chunk would result in multiple output chunks, then the first
|
||||
// outputted bit calls the readcb, and subsequent chunks just go into
|
||||
// the read buffer, and will cause it to emit 'readable' if necessary.
|
||||
//
|
||||
// This way, back-pressure is actually determined by the reading side,
|
||||
// since _read has to be called to start processing a new chunk. However,
|
||||
// a pathological inflate type of transform can cause excessive buffering
|
||||
// here. For example, imagine a stream where every byte of input is
|
||||
// interpreted as an integer from 0-255, and then results in that many
|
||||
// bytes of output. Writing the 4 bytes {ff,ff,ff,ff} would result in
|
||||
// 1kb of data being output. In this case, you could write a very small
|
||||
// amount of input, and end up with a very large amount of output. In
|
||||
// such a pathological inflating mechanism, there'd be no way to tell
|
||||
// the system to stop doing the transform. A single 4MB write could
|
||||
// cause the system to run out of memory.
|
||||
//
|
||||
// However, even in such a pathological case, only a single written chunk
|
||||
// would be consumed, and then the rest would wait (un-transformed) until
|
||||
// the results of the previous transformed chunk were consumed.
|
||||
|
||||
'use strict';
|
||||
|
||||
module.exports = Transform;
|
||||
|
||||
var Duplex = require('./_stream_duplex');
|
||||
|
||||
/*<replacement>*/
|
||||
var util = require('core-util-is');
|
||||
util.inherits = require('inherits');
|
||||
/*</replacement>*/
|
||||
|
||||
util.inherits(Transform, Duplex);
|
||||
|
||||
function TransformState(stream) {
|
||||
this.afterTransform = function (er, data) {
|
||||
return afterTransform(stream, er, data);
|
||||
};
|
||||
|
||||
this.needTransform = false;
|
||||
this.transforming = false;
|
||||
this.writecb = null;
|
||||
this.writechunk = null;
|
||||
this.writeencoding = null;
|
||||
}
|
||||
|
||||
function afterTransform(stream, er, data) {
|
||||
var ts = stream._transformState;
|
||||
ts.transforming = false;
|
||||
|
||||
var cb = ts.writecb;
|
||||
|
||||
if (!cb) return stream.emit('error', new Error('no writecb in Transform class'));
|
||||
|
||||
ts.writechunk = null;
|
||||
ts.writecb = null;
|
||||
|
||||
if (data !== null && data !== undefined) stream.push(data);
|
||||
|
||||
cb(er);
|
||||
|
||||
var rs = stream._readableState;
|
||||
rs.reading = false;
|
||||
if (rs.needReadable || rs.length < rs.highWaterMark) {
|
||||
stream._read(rs.highWaterMark);
|
||||
}
|
||||
}
|
||||
|
||||
function Transform(options) {
|
||||
if (!(this instanceof Transform)) return new Transform(options);
|
||||
|
||||
Duplex.call(this, options);
|
||||
|
||||
this._transformState = new TransformState(this);
|
||||
|
||||
var stream = this;
|
||||
|
||||
// start out asking for a readable event once data is transformed.
|
||||
this._readableState.needReadable = true;
|
||||
|
||||
// we have implemented the _read method, and done the other things
|
||||
// that Readable wants before the first _read call, so unset the
|
||||
// sync guard flag.
|
||||
this._readableState.sync = false;
|
||||
|
||||
if (options) {
|
||||
if (typeof options.transform === 'function') this._transform = options.transform;
|
||||
|
||||
if (typeof options.flush === 'function') this._flush = options.flush;
|
||||
}
|
||||
|
||||
// When the writable side finishes, then flush out anything remaining.
|
||||
this.once('prefinish', function () {
|
||||
if (typeof this._flush === 'function') this._flush(function (er, data) {
|
||||
done(stream, er, data);
|
||||
});else done(stream);
|
||||
});
|
||||
}
|
||||
|
||||
Transform.prototype.push = function (chunk, encoding) {
|
||||
this._transformState.needTransform = false;
|
||||
return Duplex.prototype.push.call(this, chunk, encoding);
|
||||
};
|
||||
|
||||
// This is the part where you do stuff!
|
||||
// override this function in implementation classes.
|
||||
// 'chunk' is an input chunk.
|
||||
//
|
||||
// Call `push(newChunk)` to pass along transformed output
|
||||
// to the readable side. You may call 'push' zero or more times.
|
||||
//
|
||||
// Call `cb(err)` when you are done with this chunk. If you pass
|
||||
// an error, then that'll put the hurt on the whole operation. If you
|
||||
// never call cb(), then you'll never get another chunk.
|
||||
Transform.prototype._transform = function (chunk, encoding, cb) {
|
||||
throw new Error('_transform() is not implemented');
|
||||
};
|
||||
|
||||
Transform.prototype._write = function (chunk, encoding, cb) {
|
||||
var ts = this._transformState;
|
||||
ts.writecb = cb;
|
||||
ts.writechunk = chunk;
|
||||
ts.writeencoding = encoding;
|
||||
if (!ts.transforming) {
|
||||
var rs = this._readableState;
|
||||
if (ts.needTransform || rs.needReadable || rs.length < rs.highWaterMark) this._read(rs.highWaterMark);
|
||||
}
|
||||
};
|
||||
|
||||
// Doesn't matter what the args are here.
|
||||
// _transform does all the work.
|
||||
// That we got here means that the readable side wants more data.
|
||||
Transform.prototype._read = function (n) {
|
||||
var ts = this._transformState;
|
||||
|
||||
if (ts.writechunk !== null && ts.writecb && !ts.transforming) {
|
||||
ts.transforming = true;
|
||||
this._transform(ts.writechunk, ts.writeencoding, ts.afterTransform);
|
||||
} else {
|
||||
// mark that we need a transform, so that any data that comes in
|
||||
// will get processed, now that we've asked for it.
|
||||
ts.needTransform = true;
|
||||
}
|
||||
};
|
||||
|
||||
function done(stream, er, data) {
|
||||
if (er) return stream.emit('error', er);
|
||||
|
||||
if (data !== null && data !== undefined) stream.push(data);
|
||||
|
||||
// if there's nothing in the write buffer, then that means
|
||||
// that nothing more will ever be provided
|
||||
var ws = stream._writableState;
|
||||
var ts = stream._transformState;
|
||||
|
||||
if (ws.length) throw new Error('Calling transform done when ws.length != 0');
|
||||
|
||||
if (ts.transforming) throw new Error('Calling transform done when still transforming');
|
||||
|
||||
return stream.push(null);
|
||||
}
|
||||
544
node_modules/readdirp/node_modules/readable-stream/lib/_stream_writable.js
generated
vendored
Normal file
544
node_modules/readdirp/node_modules/readable-stream/lib/_stream_writable.js
generated
vendored
Normal file
@@ -0,0 +1,544 @@
|
||||
// A bit simpler than readable streams.
|
||||
// Implement an async ._write(chunk, encoding, cb), and it'll handle all
|
||||
// the drain event emission and buffering.
|
||||
|
||||
'use strict';
|
||||
|
||||
module.exports = Writable;
|
||||
|
||||
/*<replacement>*/
|
||||
var processNextTick = require('process-nextick-args');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var asyncWrite = !process.browser && ['v0.10', 'v0.9.'].indexOf(process.version.slice(0, 5)) > -1 ? setImmediate : processNextTick;
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var Duplex;
|
||||
/*</replacement>*/
|
||||
|
||||
Writable.WritableState = WritableState;
|
||||
|
||||
/*<replacement>*/
|
||||
var util = require('core-util-is');
|
||||
util.inherits = require('inherits');
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var internalUtil = {
|
||||
deprecate: require('util-deprecate')
|
||||
};
|
||||
/*</replacement>*/
|
||||
|
||||
/*<replacement>*/
|
||||
var Stream = require('./internal/streams/stream');
|
||||
/*</replacement>*/
|
||||
|
||||
var Buffer = require('buffer').Buffer;
|
||||
/*<replacement>*/
|
||||
var bufferShim = require('buffer-shims');
|
||||
/*</replacement>*/
|
||||
|
||||
util.inherits(Writable, Stream);
|
||||
|
||||
function nop() {}
|
||||
|
||||
function WriteReq(chunk, encoding, cb) {
|
||||
this.chunk = chunk;
|
||||
this.encoding = encoding;
|
||||
this.callback = cb;
|
||||
this.next = null;
|
||||
}
|
||||
|
||||
function WritableState(options, stream) {
|
||||
Duplex = Duplex || require('./_stream_duplex');
|
||||
|
||||
options = options || {};
|
||||
|
||||
// object stream flag to indicate whether or not this stream
|
||||
// contains buffers or objects.
|
||||
this.objectMode = !!options.objectMode;
|
||||
|
||||
if (stream instanceof Duplex) this.objectMode = this.objectMode || !!options.writableObjectMode;
|
||||
|
||||
// the point at which write() starts returning false
|
||||
// Note: 0 is a valid value, means that we always return false if
|
||||
// the entire buffer is not flushed immediately on write()
|
||||
var hwm = options.highWaterMark;
|
||||
var defaultHwm = this.objectMode ? 16 : 16 * 1024;
|
||||
this.highWaterMark = hwm || hwm === 0 ? hwm : defaultHwm;
|
||||
|
||||
// cast to ints.
|
||||
this.highWaterMark = ~~this.highWaterMark;
|
||||
|
||||
// drain event flag.
|
||||
this.needDrain = false;
|
||||
// at the start of calling end()
|
||||
this.ending = false;
|
||||
// when end() has been called, and returned
|
||||
this.ended = false;
|
||||
// when 'finish' is emitted
|
||||
this.finished = false;
|
||||
|
||||
// should we decode strings into buffers before passing to _write?
|
||||
// this is here so that some node-core streams can optimize string
|
||||
// handling at a lower level.
|
||||
var noDecode = options.decodeStrings === false;
|
||||
this.decodeStrings = !noDecode;
|
||||
|
||||
// Crypto is kind of old and crusty. Historically, its default string
|
||||
// encoding is 'binary' so we have to make this configurable.
|
||||
// Everything else in the universe uses 'utf8', though.
|
||||
this.defaultEncoding = options.defaultEncoding || 'utf8';
|
||||
|
||||
// not an actual buffer we keep track of, but a measurement
|
||||
// of how much we're waiting to get pushed to some underlying
|
||||
// socket or file.
|
||||
this.length = 0;
|
||||
|
||||
// a flag to see when we're in the middle of a write.
|
||||
this.writing = false;
|
||||
|
||||
// when true all writes will be buffered until .uncork() call
|
||||
this.corked = 0;
|
||||
|
||||
// a flag to be able to tell if the onwrite cb is called immediately,
|
||||
// or on a later tick. We set this to true at first, because any
|
||||
// actions that shouldn't happen until "later" should generally also
|
||||
// not happen before the first write call.
|
||||
this.sync = true;
|
||||
|
||||
// a flag to know if we're processing previously buffered items, which
|
||||
// may call the _write() callback in the same tick, so that we don't
|
||||
// end up in an overlapped onwrite situation.
|
||||
this.bufferProcessing = false;
|
||||
|
||||
// the callback that's passed to _write(chunk,cb)
|
||||
this.onwrite = function (er) {
|
||||
onwrite(stream, er);
|
||||
};
|
||||
|
||||
// the callback that the user supplies to write(chunk,encoding,cb)
|
||||
this.writecb = null;
|
||||
|
||||
// the amount that is being written when _write is called.
|
||||
this.writelen = 0;
|
||||
|
||||
this.bufferedRequest = null;
|
||||
this.lastBufferedRequest = null;
|
||||
|
||||
// number of pending user-supplied write callbacks
|
||||
// this must be 0 before 'finish' can be emitted
|
||||
this.pendingcb = 0;
|
||||
|
||||
// emit prefinish if the only thing we're waiting for is _write cbs
|
||||
// This is relevant for synchronous Transform streams
|
||||
this.prefinished = false;
|
||||
|
||||
// True if the error was already emitted and should not be thrown again
|
||||
this.errorEmitted = false;
|
||||
|
||||
// count buffered requests
|
||||
this.bufferedRequestCount = 0;
|
||||
|
||||
// allocate the first CorkedRequest, there is always
|
||||
// one allocated and free to use, and we maintain at most two
|
||||
this.corkedRequestsFree = new CorkedRequest(this);
|
||||
}
|
||||
|
||||
WritableState.prototype.getBuffer = function getBuffer() {
|
||||
var current = this.bufferedRequest;
|
||||
var out = [];
|
||||
while (current) {
|
||||
out.push(current);
|
||||
current = current.next;
|
||||
}
|
||||
return out;
|
||||
};
|
||||
|
||||
(function () {
|
||||
try {
|
||||
Object.defineProperty(WritableState.prototype, 'buffer', {
|
||||
get: internalUtil.deprecate(function () {
|
||||
return this.getBuffer();
|
||||
}, '_writableState.buffer is deprecated. Use _writableState.getBuffer ' + 'instead.')
|
||||
});
|
||||
} catch (_) {}
|
||||
})();
|
||||
|
||||
// Test _writableState for inheritance to account for Duplex streams,
|
||||
// whose prototype chain only points to Readable.
|
||||
var realHasInstance;
|
||||
if (typeof Symbol === 'function' && Symbol.hasInstance && typeof Function.prototype[Symbol.hasInstance] === 'function') {
|
||||
realHasInstance = Function.prototype[Symbol.hasInstance];
|
||||
Object.defineProperty(Writable, Symbol.hasInstance, {
|
||||
value: function (object) {
|
||||
if (realHasInstance.call(this, object)) return true;
|
||||
|
||||
return object && object._writableState instanceof WritableState;
|
||||
}
|
||||
});
|
||||
} else {
|
||||
realHasInstance = function (object) {
|
||||
return object instanceof this;
|
||||
};
|
||||
}
|
||||
|
||||
function Writable(options) {
|
||||
Duplex = Duplex || require('./_stream_duplex');
|
||||
|
||||
// Writable ctor is applied to Duplexes, too.
|
||||
// `realHasInstance` is necessary because using plain `instanceof`
|
||||
// would return false, as no `_writableState` property is attached.
|
||||
|
||||
// Trying to use the custom `instanceof` for Writable here will also break the
|
||||
// Node.js LazyTransform implementation, which has a non-trivial getter for
|
||||
// `_writableState` that would lead to infinite recursion.
|
||||
if (!realHasInstance.call(Writable, this) && !(this instanceof Duplex)) {
|
||||
return new Writable(options);
|
||||
}
|
||||
|
||||
this._writableState = new WritableState(options, this);
|
||||
|
||||
// legacy.
|
||||
this.writable = true;
|
||||
|
||||
if (options) {
|
||||
if (typeof options.write === 'function') this._write = options.write;
|
||||
|
||||
if (typeof options.writev === 'function') this._writev = options.writev;
|
||||
}
|
||||
|
||||
Stream.call(this);
|
||||
}
|
||||
|
||||
// Otherwise people can pipe Writable streams, which is just wrong.
|
||||
Writable.prototype.pipe = function () {
|
||||
this.emit('error', new Error('Cannot pipe, not readable'));
|
||||
};
|
||||
|
||||
function writeAfterEnd(stream, cb) {
|
||||
var er = new Error('write after end');
|
||||
// TODO: defer error events consistently everywhere, not just the cb
|
||||
stream.emit('error', er);
|
||||
processNextTick(cb, er);
|
||||
}
|
||||
|
||||
// Checks that a user-supplied chunk is valid, especially for the particular
|
||||
// mode the stream is in. Currently this means that `null` is never accepted
|
||||
// and undefined/non-string values are only allowed in object mode.
|
||||
function validChunk(stream, state, chunk, cb) {
|
||||
var valid = true;
|
||||
var er = false;
|
||||
|
||||
if (chunk === null) {
|
||||
er = new TypeError('May not write null values to stream');
|
||||
} else if (typeof chunk !== 'string' && chunk !== undefined && !state.objectMode) {
|
||||
er = new TypeError('Invalid non-string/buffer chunk');
|
||||
}
|
||||
if (er) {
|
||||
stream.emit('error', er);
|
||||
processNextTick(cb, er);
|
||||
valid = false;
|
||||
}
|
||||
return valid;
|
||||
}
|
||||
|
||||
Writable.prototype.write = function (chunk, encoding, cb) {
|
||||
var state = this._writableState;
|
||||
var ret = false;
|
||||
var isBuf = Buffer.isBuffer(chunk);
|
||||
|
||||
if (typeof encoding === 'function') {
|
||||
cb = encoding;
|
||||
encoding = null;
|
||||
}
|
||||
|
||||
if (isBuf) encoding = 'buffer';else if (!encoding) encoding = state.defaultEncoding;
|
||||
|
||||
if (typeof cb !== 'function') cb = nop;
|
||||
|
||||
if (state.ended) writeAfterEnd(this, cb);else if (isBuf || validChunk(this, state, chunk, cb)) {
|
||||
state.pendingcb++;
|
||||
ret = writeOrBuffer(this, state, isBuf, chunk, encoding, cb);
|
||||
}
|
||||
|
||||
return ret;
|
||||
};
|
||||
|
||||
Writable.prototype.cork = function () {
|
||||
var state = this._writableState;
|
||||
|
||||
state.corked++;
|
||||
};
|
||||
|
||||
Writable.prototype.uncork = function () {
|
||||
var state = this._writableState;
|
||||
|
||||
if (state.corked) {
|
||||
state.corked--;
|
||||
|
||||
if (!state.writing && !state.corked && !state.finished && !state.bufferProcessing && state.bufferedRequest) clearBuffer(this, state);
|
||||
}
|
||||
};
|
||||
|
||||
Writable.prototype.setDefaultEncoding = function setDefaultEncoding(encoding) {
|
||||
// node::ParseEncoding() requires lower case.
|
||||
if (typeof encoding === 'string') encoding = encoding.toLowerCase();
|
||||
if (!(['hex', 'utf8', 'utf-8', 'ascii', 'binary', 'base64', 'ucs2', 'ucs-2', 'utf16le', 'utf-16le', 'raw'].indexOf((encoding + '').toLowerCase()) > -1)) throw new TypeError('Unknown encoding: ' + encoding);
|
||||
this._writableState.defaultEncoding = encoding;
|
||||
return this;
|
||||
};
|
||||
|
||||
function decodeChunk(state, chunk, encoding) {
|
||||
if (!state.objectMode && state.decodeStrings !== false && typeof chunk === 'string') {
|
||||
chunk = bufferShim.from(chunk, encoding);
|
||||
}
|
||||
return chunk;
|
||||
}
|
||||
|
||||
// if we're already writing something, then just put this
|
||||
// in the queue, and wait our turn. Otherwise, call _write
|
||||
// If we return false, then we need a drain event, so set that flag.
|
||||
function writeOrBuffer(stream, state, isBuf, chunk, encoding, cb) {
|
||||
if (!isBuf) {
|
||||
chunk = decodeChunk(state, chunk, encoding);
|
||||
if (Buffer.isBuffer(chunk)) encoding = 'buffer';
|
||||
}
|
||||
var len = state.objectMode ? 1 : chunk.length;
|
||||
|
||||
state.length += len;
|
||||
|
||||
var ret = state.length < state.highWaterMark;
|
||||
// we must ensure that previous needDrain will not be reset to false.
|
||||
if (!ret) state.needDrain = true;
|
||||
|
||||
if (state.writing || state.corked) {
|
||||
var last = state.lastBufferedRequest;
|
||||
state.lastBufferedRequest = new WriteReq(chunk, encoding, cb);
|
||||
if (last) {
|
||||
last.next = state.lastBufferedRequest;
|
||||
} else {
|
||||
state.bufferedRequest = state.lastBufferedRequest;
|
||||
}
|
||||
state.bufferedRequestCount += 1;
|
||||
} else {
|
||||
doWrite(stream, state, false, len, chunk, encoding, cb);
|
||||
}
|
||||
|
||||
return ret;
|
||||
}
|
||||
|
||||
function doWrite(stream, state, writev, len, chunk, encoding, cb) {
|
||||
state.writelen = len;
|
||||
state.writecb = cb;
|
||||
state.writing = true;
|
||||
state.sync = true;
|
||||
if (writev) stream._writev(chunk, state.onwrite);else stream._write(chunk, encoding, state.onwrite);
|
||||
state.sync = false;
|
||||
}
|
||||
|
||||
function onwriteError(stream, state, sync, er, cb) {
|
||||
--state.pendingcb;
|
||||
if (sync) processNextTick(cb, er);else cb(er);
|
||||
|
||||
stream._writableState.errorEmitted = true;
|
||||
stream.emit('error', er);
|
||||
}
|
||||
|
||||
function onwriteStateUpdate(state) {
|
||||
state.writing = false;
|
||||
state.writecb = null;
|
||||
state.length -= state.writelen;
|
||||
state.writelen = 0;
|
||||
}
|
||||
|
||||
function onwrite(stream, er) {
|
||||
var state = stream._writableState;
|
||||
var sync = state.sync;
|
||||
var cb = state.writecb;
|
||||
|
||||
onwriteStateUpdate(state);
|
||||
|
||||
if (er) onwriteError(stream, state, sync, er, cb);else {
|
||||
// Check if we're actually ready to finish, but don't emit yet
|
||||
var finished = needFinish(state);
|
||||
|
||||
if (!finished && !state.corked && !state.bufferProcessing && state.bufferedRequest) {
|
||||
clearBuffer(stream, state);
|
||||
}
|
||||
|
||||
if (sync) {
|
||||
/*<replacement>*/
|
||||
asyncWrite(afterWrite, stream, state, finished, cb);
|
||||
/*</replacement>*/
|
||||
} else {
|
||||
afterWrite(stream, state, finished, cb);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function afterWrite(stream, state, finished, cb) {
|
||||
if (!finished) onwriteDrain(stream, state);
|
||||
state.pendingcb--;
|
||||
cb();
|
||||
finishMaybe(stream, state);
|
||||
}
|
||||
|
||||
// Must force callback to be called on nextTick, so that we don't
|
||||
// emit 'drain' before the write() consumer gets the 'false' return
|
||||
// value, and has a chance to attach a 'drain' listener.
|
||||
function onwriteDrain(stream, state) {
|
||||
if (state.length === 0 && state.needDrain) {
|
||||
state.needDrain = false;
|
||||
stream.emit('drain');
|
||||
}
|
||||
}
|
||||
|
||||
// if there's something in the buffer waiting, then process it
|
||||
function clearBuffer(stream, state) {
|
||||
state.bufferProcessing = true;
|
||||
var entry = state.bufferedRequest;
|
||||
|
||||
if (stream._writev && entry && entry.next) {
|
||||
// Fast case, write everything using _writev()
|
||||
var l = state.bufferedRequestCount;
|
||||
var buffer = new Array(l);
|
||||
var holder = state.corkedRequestsFree;
|
||||
holder.entry = entry;
|
||||
|
||||
var count = 0;
|
||||
while (entry) {
|
||||
buffer[count] = entry;
|
||||
entry = entry.next;
|
||||
count += 1;
|
||||
}
|
||||
|
||||
doWrite(stream, state, true, state.length, buffer, '', holder.finish);
|
||||
|
||||
// doWrite is almost always async, defer these to save a bit of time
|
||||
// as the hot path ends with doWrite
|
||||
state.pendingcb++;
|
||||
state.lastBufferedRequest = null;
|
||||
if (holder.next) {
|
||||
state.corkedRequestsFree = holder.next;
|
||||
holder.next = null;
|
||||
} else {
|
||||
state.corkedRequestsFree = new CorkedRequest(state);
|
||||
}
|
||||
} else {
|
||||
// Slow case, write chunks one-by-one
|
||||
while (entry) {
|
||||
var chunk = entry.chunk;
|
||||
var encoding = entry.encoding;
|
||||
var cb = entry.callback;
|
||||
var len = state.objectMode ? 1 : chunk.length;
|
||||
|
||||
doWrite(stream, state, false, len, chunk, encoding, cb);
|
||||
entry = entry.next;
|
||||
// if we didn't call the onwrite immediately, then
|
||||
// it means that we need to wait until it does.
|
||||
// also, that means that the chunk and cb are currently
|
||||
// being processed, so move the buffer counter past them.
|
||||
if (state.writing) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
if (entry === null) state.lastBufferedRequest = null;
|
||||
}
|
||||
|
||||
state.bufferedRequestCount = 0;
|
||||
state.bufferedRequest = entry;
|
||||
state.bufferProcessing = false;
|
||||
}
|
||||
|
||||
Writable.prototype._write = function (chunk, encoding, cb) {
|
||||
cb(new Error('_write() is not implemented'));
|
||||
};
|
||||
|
||||
Writable.prototype._writev = null;
|
||||
|
||||
Writable.prototype.end = function (chunk, encoding, cb) {
|
||||
var state = this._writableState;
|
||||
|
||||
if (typeof chunk === 'function') {
|
||||
cb = chunk;
|
||||
chunk = null;
|
||||
encoding = null;
|
||||
} else if (typeof encoding === 'function') {
|
||||
cb = encoding;
|
||||
encoding = null;
|
||||
}
|
||||
|
||||
if (chunk !== null && chunk !== undefined) this.write(chunk, encoding);
|
||||
|
||||
// .end() fully uncorks
|
||||
if (state.corked) {
|
||||
state.corked = 1;
|
||||
this.uncork();
|
||||
}
|
||||
|
||||
// ignore unnecessary end() calls.
|
||||
if (!state.ending && !state.finished) endWritable(this, state, cb);
|
||||
};
|
||||
|
||||
function needFinish(state) {
|
||||
return state.ending && state.length === 0 && state.bufferedRequest === null && !state.finished && !state.writing;
|
||||
}
|
||||
|
||||
function prefinish(stream, state) {
|
||||
if (!state.prefinished) {
|
||||
state.prefinished = true;
|
||||
stream.emit('prefinish');
|
||||
}
|
||||
}
|
||||
|
||||
function finishMaybe(stream, state) {
|
||||
var need = needFinish(state);
|
||||
if (need) {
|
||||
if (state.pendingcb === 0) {
|
||||
prefinish(stream, state);
|
||||
state.finished = true;
|
||||
stream.emit('finish');
|
||||
} else {
|
||||
prefinish(stream, state);
|
||||
}
|
||||
}
|
||||
return need;
|
||||
}
|
||||
|
||||
function endWritable(stream, state, cb) {
|
||||
state.ending = true;
|
||||
finishMaybe(stream, state);
|
||||
if (cb) {
|
||||
if (state.finished) processNextTick(cb);else stream.once('finish', cb);
|
||||
}
|
||||
state.ended = true;
|
||||
stream.writable = false;
|
||||
}
|
||||
|
||||
// It seems a linked list but it is not
|
||||
// there will be only 2 of these for each stream
|
||||
function CorkedRequest(state) {
|
||||
var _this = this;
|
||||
|
||||
this.next = null;
|
||||
this.entry = null;
|
||||
this.finish = function (err) {
|
||||
var entry = _this.entry;
|
||||
_this.entry = null;
|
||||
while (entry) {
|
||||
var cb = entry.callback;
|
||||
state.pendingcb--;
|
||||
cb(err);
|
||||
entry = entry.next;
|
||||
}
|
||||
if (state.corkedRequestsFree) {
|
||||
state.corkedRequestsFree.next = _this;
|
||||
} else {
|
||||
state.corkedRequestsFree = _this;
|
||||
}
|
||||
};
|
||||
}
|
||||
64
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/BufferList.js
generated
vendored
Normal file
64
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/BufferList.js
generated
vendored
Normal file
@@ -0,0 +1,64 @@
|
||||
'use strict';
|
||||
|
||||
var Buffer = require('buffer').Buffer;
|
||||
/*<replacement>*/
|
||||
var bufferShim = require('buffer-shims');
|
||||
/*</replacement>*/
|
||||
|
||||
module.exports = BufferList;
|
||||
|
||||
function BufferList() {
|
||||
this.head = null;
|
||||
this.tail = null;
|
||||
this.length = 0;
|
||||
}
|
||||
|
||||
BufferList.prototype.push = function (v) {
|
||||
var entry = { data: v, next: null };
|
||||
if (this.length > 0) this.tail.next = entry;else this.head = entry;
|
||||
this.tail = entry;
|
||||
++this.length;
|
||||
};
|
||||
|
||||
BufferList.prototype.unshift = function (v) {
|
||||
var entry = { data: v, next: this.head };
|
||||
if (this.length === 0) this.tail = entry;
|
||||
this.head = entry;
|
||||
++this.length;
|
||||
};
|
||||
|
||||
BufferList.prototype.shift = function () {
|
||||
if (this.length === 0) return;
|
||||
var ret = this.head.data;
|
||||
if (this.length === 1) this.head = this.tail = null;else this.head = this.head.next;
|
||||
--this.length;
|
||||
return ret;
|
||||
};
|
||||
|
||||
BufferList.prototype.clear = function () {
|
||||
this.head = this.tail = null;
|
||||
this.length = 0;
|
||||
};
|
||||
|
||||
BufferList.prototype.join = function (s) {
|
||||
if (this.length === 0) return '';
|
||||
var p = this.head;
|
||||
var ret = '' + p.data;
|
||||
while (p = p.next) {
|
||||
ret += s + p.data;
|
||||
}return ret;
|
||||
};
|
||||
|
||||
BufferList.prototype.concat = function (n) {
|
||||
if (this.length === 0) return bufferShim.alloc(0);
|
||||
if (this.length === 1) return this.head.data;
|
||||
var ret = bufferShim.allocUnsafe(n >>> 0);
|
||||
var p = this.head;
|
||||
var i = 0;
|
||||
while (p) {
|
||||
p.data.copy(ret, i);
|
||||
i += p.data.length;
|
||||
p = p.next;
|
||||
}
|
||||
return ret;
|
||||
};
|
||||
1
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/stream-browser.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/stream-browser.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('events').EventEmitter;
|
||||
1
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/stream.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/lib/internal/streams/stream.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('stream');
|
||||
134
node_modules/readdirp/node_modules/readable-stream/package.json
generated
vendored
Normal file
134
node_modules/readdirp/node_modules/readable-stream/package.json
generated
vendored
Normal file
@@ -0,0 +1,134 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "readable-stream@^2.0.2",
|
||||
"scope": null,
|
||||
"escapedName": "readable-stream",
|
||||
"name": "readable-stream",
|
||||
"rawSpec": "^2.0.2",
|
||||
"spec": ">=2.0.2 <3.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp"
|
||||
]
|
||||
],
|
||||
"_from": "readable-stream@>=2.0.2 <3.0.0",
|
||||
"_id": "readable-stream@2.2.9",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp/readable-stream",
|
||||
"_nodeVersion": "6.10.1",
|
||||
"_npmOperationalInternal": {
|
||||
"host": "packages-12-west.internal.npmjs.com",
|
||||
"tmp": "tmp/readable-stream-2.2.9.tgz_1491638759718_0.9035766560118645"
|
||||
},
|
||||
"_npmUser": {
|
||||
"name": "matteo.collina",
|
||||
"email": "hello@matteocollina.com"
|
||||
},
|
||||
"_npmVersion": "3.10.10",
|
||||
"_phantomChildren": {},
|
||||
"_requested": {
|
||||
"raw": "readable-stream@^2.0.2",
|
||||
"scope": null,
|
||||
"escapedName": "readable-stream",
|
||||
"name": "readable-stream",
|
||||
"rawSpec": "^2.0.2",
|
||||
"spec": ">=2.0.2 <3.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/readdirp"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/readable-stream/-/readable-stream-2.2.9.tgz",
|
||||
"_shasum": "cf78ec6f4a6d1eb43d26488cac97f042e74b7fc8",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "readable-stream@^2.0.2",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp",
|
||||
"browser": {
|
||||
"util": false,
|
||||
"./readable.js": "./readable-browser.js",
|
||||
"./writable.js": "./writable-browser.js",
|
||||
"./duplex.js": "./duplex-browser.js",
|
||||
"./lib/internal/streams/stream.js": "./lib/internal/streams/stream-browser.js"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/nodejs/readable-stream/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"buffer-shims": "~1.0.0",
|
||||
"core-util-is": "~1.0.0",
|
||||
"inherits": "~2.0.1",
|
||||
"isarray": "~1.0.0",
|
||||
"process-nextick-args": "~1.0.6",
|
||||
"string_decoder": "~1.0.0",
|
||||
"util-deprecate": "~1.0.1"
|
||||
},
|
||||
"description": "Streams3, a user-land copy of the stream library from Node.js",
|
||||
"devDependencies": {
|
||||
"assert": "~1.4.0",
|
||||
"babel-polyfill": "^6.9.1",
|
||||
"buffer": "^4.9.0",
|
||||
"nyc": "^6.4.0",
|
||||
"tap": "~0.7.1",
|
||||
"tape": "~4.5.1",
|
||||
"zuul": "~3.10.0"
|
||||
},
|
||||
"directories": {},
|
||||
"dist": {
|
||||
"shasum": "cf78ec6f4a6d1eb43d26488cac97f042e74b7fc8",
|
||||
"tarball": "https://registry.npmjs.org/readable-stream/-/readable-stream-2.2.9.tgz"
|
||||
},
|
||||
"gitHead": "16eca30fe46a937403502a391859ef51625bcc53",
|
||||
"homepage": "https://github.com/nodejs/readable-stream#readme",
|
||||
"keywords": [
|
||||
"readable",
|
||||
"stream",
|
||||
"pipe"
|
||||
],
|
||||
"license": "MIT",
|
||||
"main": "readable.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "cwmma",
|
||||
"email": "calvin.metcalf@gmail.com"
|
||||
},
|
||||
{
|
||||
"name": "isaacs",
|
||||
"email": "i@izs.me"
|
||||
},
|
||||
{
|
||||
"name": "matteo.collina",
|
||||
"email": "hello@matteocollina.com"
|
||||
},
|
||||
{
|
||||
"name": "rvagg",
|
||||
"email": "rod@vagg.org"
|
||||
},
|
||||
{
|
||||
"name": "tootallnate",
|
||||
"email": "nathan@tootallnate.net"
|
||||
}
|
||||
],
|
||||
"name": "readable-stream",
|
||||
"nyc": {
|
||||
"include": [
|
||||
"lib/**.js"
|
||||
]
|
||||
},
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/nodejs/readable-stream.git"
|
||||
},
|
||||
"scripts": {
|
||||
"browser": "npm run write-zuul && zuul --browser-retries 2 -- test/browser.js",
|
||||
"cover": "nyc npm test",
|
||||
"local": "zuul --local 3000 --no-coverage -- test/browser.js",
|
||||
"report": "nyc report --reporter=lcov",
|
||||
"test": "tap test/parallel/*.js test/ours/*.js",
|
||||
"write-zuul": "printf \"ui: tape\nbrowsers:\n - name: $BROWSER_NAME\n version: $BROWSER_VERSION\n\">.zuul.yml"
|
||||
},
|
||||
"version": "2.2.9"
|
||||
}
|
||||
1
node_modules/readdirp/node_modules/readable-stream/passthrough.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/passthrough.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('./readable').PassThrough
|
||||
7
node_modules/readdirp/node_modules/readable-stream/readable-browser.js
generated
vendored
Normal file
7
node_modules/readdirp/node_modules/readable-stream/readable-browser.js
generated
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
exports = module.exports = require('./lib/_stream_readable.js');
|
||||
exports.Stream = exports;
|
||||
exports.Readable = exports;
|
||||
exports.Writable = require('./lib/_stream_writable.js');
|
||||
exports.Duplex = require('./lib/_stream_duplex.js');
|
||||
exports.Transform = require('./lib/_stream_transform.js');
|
||||
exports.PassThrough = require('./lib/_stream_passthrough.js');
|
||||
19
node_modules/readdirp/node_modules/readable-stream/readable.js
generated
vendored
Normal file
19
node_modules/readdirp/node_modules/readable-stream/readable.js
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
var Stream = require('stream');
|
||||
if (process.env.READABLE_STREAM === 'disable' && Stream) {
|
||||
module.exports = Stream;
|
||||
exports = module.exports = Stream.Readable;
|
||||
exports.Readable = Stream.Readable;
|
||||
exports.Writable = Stream.Writable;
|
||||
exports.Duplex = Stream.Duplex;
|
||||
exports.Transform = Stream.Transform;
|
||||
exports.PassThrough = Stream.PassThrough;
|
||||
exports.Stream = Stream;
|
||||
} else {
|
||||
exports = module.exports = require('./lib/_stream_readable.js');
|
||||
exports.Stream = Stream || exports;
|
||||
exports.Readable = exports;
|
||||
exports.Writable = require('./lib/_stream_writable.js');
|
||||
exports.Duplex = require('./lib/_stream_duplex.js');
|
||||
exports.Transform = require('./lib/_stream_transform.js');
|
||||
exports.PassThrough = require('./lib/_stream_passthrough.js');
|
||||
}
|
||||
1
node_modules/readdirp/node_modules/readable-stream/transform.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/transform.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('./readable').Transform
|
||||
1
node_modules/readdirp/node_modules/readable-stream/writable-browser.js
generated
vendored
Normal file
1
node_modules/readdirp/node_modules/readable-stream/writable-browser.js
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module.exports = require('./lib/_stream_writable.js');
|
||||
8
node_modules/readdirp/node_modules/readable-stream/writable.js
generated
vendored
Normal file
8
node_modules/readdirp/node_modules/readable-stream/writable.js
generated
vendored
Normal file
@@ -0,0 +1,8 @@
|
||||
var Stream = require("stream")
|
||||
var Writable = require("./lib/_stream_writable.js")
|
||||
|
||||
if (process.env.READABLE_STREAM === 'disable') {
|
||||
module.exports = Stream && Stream.Writable || Writable
|
||||
}
|
||||
|
||||
module.exports = Writable
|
||||
2
node_modules/readdirp/node_modules/string_decoder/.npmignore
generated
vendored
Normal file
2
node_modules/readdirp/node_modules/string_decoder/.npmignore
generated
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
build
|
||||
test
|
||||
48
node_modules/readdirp/node_modules/string_decoder/LICENSE
generated
vendored
Normal file
48
node_modules/readdirp/node_modules/string_decoder/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,48 @@
|
||||
Node.js is licensed for use as follows:
|
||||
|
||||
"""
|
||||
Copyright Node.js contributors. All rights reserved.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to
|
||||
deal in the Software without restriction, including without limitation the
|
||||
rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
sell copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
IN THE SOFTWARE.
|
||||
"""
|
||||
|
||||
This license applies to parts of Node.js originating from the
|
||||
https://github.com/joyent/node repository:
|
||||
|
||||
"""
|
||||
Copyright Joyent, Inc. and other Node contributors. All rights reserved.
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to
|
||||
deal in the Software without restriction, including without limitation the
|
||||
rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
sell copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
IN THE SOFTWARE.
|
||||
"""
|
||||
|
||||
30
node_modules/readdirp/node_modules/string_decoder/README.md
generated
vendored
Normal file
30
node_modules/readdirp/node_modules/string_decoder/README.md
generated
vendored
Normal file
@@ -0,0 +1,30 @@
|
||||
# string_decoder
|
||||
|
||||
***Node-core v7.0.0 string_decoder for userland***
|
||||
|
||||
|
||||
[](https://nodei.co/npm/string_decoder/)
|
||||
[](https://nodei.co/npm/string_decoder/)
|
||||
|
||||
|
||||
[](https://saucelabs.com/u/string_decoder)
|
||||
|
||||
```bash
|
||||
npm install --save string_decoder
|
||||
```
|
||||
|
||||
***Node-core string_decoderstring_decoder for userland***
|
||||
|
||||
This package is a mirror of the string_decoder implementation in Node-core.
|
||||
|
||||
Full documentation may be found on the [Node.js website](https://nodejs.org/dist/v7.8.0/docs/api/).
|
||||
|
||||
As of version 1.0.0 **string_decoder** uses semantic versioning.
|
||||
|
||||
## Previous versions
|
||||
|
||||
Previous version numbers match the versions found in Node core, e.g. 0.10.24 matches Node 0.10.24, likewise 0.11.10 matches Node 0.11.10.
|
||||
|
||||
## Update
|
||||
|
||||
The *build/* directory contains a build script that will scrape the source from the [nodejs/node](https://github.com/nodejs/node) repo given a specific Node version.
|
||||
273
node_modules/readdirp/node_modules/string_decoder/lib/string_decoder.js
generated
vendored
Normal file
273
node_modules/readdirp/node_modules/string_decoder/lib/string_decoder.js
generated
vendored
Normal file
@@ -0,0 +1,273 @@
|
||||
'use strict';
|
||||
|
||||
var Buffer = require('buffer').Buffer;
|
||||
var bufferShim = require('buffer-shims');
|
||||
|
||||
var isEncoding = Buffer.isEncoding || function (encoding) {
|
||||
encoding = '' + encoding;
|
||||
switch (encoding && encoding.toLowerCase()) {
|
||||
case 'hex':case 'utf8':case 'utf-8':case 'ascii':case 'binary':case 'base64':case 'ucs2':case 'ucs-2':case 'utf16le':case 'utf-16le':case 'raw':
|
||||
return true;
|
||||
default:
|
||||
return false;
|
||||
}
|
||||
};
|
||||
|
||||
function _normalizeEncoding(enc) {
|
||||
if (!enc) return 'utf8';
|
||||
var retried;
|
||||
while (true) {
|
||||
switch (enc) {
|
||||
case 'utf8':
|
||||
case 'utf-8':
|
||||
return 'utf8';
|
||||
case 'ucs2':
|
||||
case 'ucs-2':
|
||||
case 'utf16le':
|
||||
case 'utf-16le':
|
||||
return 'utf16le';
|
||||
case 'latin1':
|
||||
case 'binary':
|
||||
return 'latin1';
|
||||
case 'base64':
|
||||
case 'ascii':
|
||||
case 'hex':
|
||||
return enc;
|
||||
default:
|
||||
if (retried) return; // undefined
|
||||
enc = ('' + enc).toLowerCase();
|
||||
retried = true;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
// Do not cache `Buffer.isEncoding` when checking encoding names as some
|
||||
// modules monkey-patch it to support additional encodings
|
||||
function normalizeEncoding(enc) {
|
||||
var nenc = _normalizeEncoding(enc);
|
||||
if (typeof nenc !== 'string' && (Buffer.isEncoding === isEncoding || !isEncoding(enc))) throw new Error('Unknown encoding: ' + enc);
|
||||
return nenc || enc;
|
||||
}
|
||||
|
||||
// StringDecoder provides an interface for efficiently splitting a series of
|
||||
// buffers into a series of JS strings without breaking apart multi-byte
|
||||
// characters.
|
||||
exports.StringDecoder = StringDecoder;
|
||||
function StringDecoder(encoding) {
|
||||
this.encoding = normalizeEncoding(encoding);
|
||||
var nb;
|
||||
switch (this.encoding) {
|
||||
case 'utf16le':
|
||||
this.text = utf16Text;
|
||||
this.end = utf16End;
|
||||
nb = 4;
|
||||
break;
|
||||
case 'utf8':
|
||||
this.fillLast = utf8FillLast;
|
||||
nb = 4;
|
||||
break;
|
||||
case 'base64':
|
||||
this.text = base64Text;
|
||||
this.end = base64End;
|
||||
nb = 3;
|
||||
break;
|
||||
default:
|
||||
this.write = simpleWrite;
|
||||
this.end = simpleEnd;
|
||||
return;
|
||||
}
|
||||
this.lastNeed = 0;
|
||||
this.lastTotal = 0;
|
||||
this.lastChar = bufferShim.allocUnsafe(nb);
|
||||
}
|
||||
|
||||
StringDecoder.prototype.write = function (buf) {
|
||||
if (buf.length === 0) return '';
|
||||
var r;
|
||||
var i;
|
||||
if (this.lastNeed) {
|
||||
r = this.fillLast(buf);
|
||||
if (r === undefined) return '';
|
||||
i = this.lastNeed;
|
||||
this.lastNeed = 0;
|
||||
} else {
|
||||
i = 0;
|
||||
}
|
||||
if (i < buf.length) return r ? r + this.text(buf, i) : this.text(buf, i);
|
||||
return r || '';
|
||||
};
|
||||
|
||||
StringDecoder.prototype.end = utf8End;
|
||||
|
||||
// Returns only complete characters in a Buffer
|
||||
StringDecoder.prototype.text = utf8Text;
|
||||
|
||||
// Attempts to complete a partial non-UTF-8 character using bytes from a Buffer
|
||||
StringDecoder.prototype.fillLast = function (buf) {
|
||||
if (this.lastNeed <= buf.length) {
|
||||
buf.copy(this.lastChar, this.lastTotal - this.lastNeed, 0, this.lastNeed);
|
||||
return this.lastChar.toString(this.encoding, 0, this.lastTotal);
|
||||
}
|
||||
buf.copy(this.lastChar, this.lastTotal - this.lastNeed, 0, buf.length);
|
||||
this.lastNeed -= buf.length;
|
||||
};
|
||||
|
||||
// Checks the type of a UTF-8 byte, whether it's ASCII, a leading byte, or a
|
||||
// continuation byte.
|
||||
function utf8CheckByte(byte) {
|
||||
if (byte <= 0x7F) return 0;else if (byte >> 5 === 0x06) return 2;else if (byte >> 4 === 0x0E) return 3;else if (byte >> 3 === 0x1E) return 4;
|
||||
return -1;
|
||||
}
|
||||
|
||||
// Checks at most 3 bytes at the end of a Buffer in order to detect an
|
||||
// incomplete multi-byte UTF-8 character. The total number of bytes (2, 3, or 4)
|
||||
// needed to complete the UTF-8 character (if applicable) are returned.
|
||||
function utf8CheckIncomplete(self, buf, i) {
|
||||
var j = buf.length - 1;
|
||||
if (j < i) return 0;
|
||||
var nb = utf8CheckByte(buf[j]);
|
||||
if (nb >= 0) {
|
||||
if (nb > 0) self.lastNeed = nb - 1;
|
||||
return nb;
|
||||
}
|
||||
if (--j < i) return 0;
|
||||
nb = utf8CheckByte(buf[j]);
|
||||
if (nb >= 0) {
|
||||
if (nb > 0) self.lastNeed = nb - 2;
|
||||
return nb;
|
||||
}
|
||||
if (--j < i) return 0;
|
||||
nb = utf8CheckByte(buf[j]);
|
||||
if (nb >= 0) {
|
||||
if (nb > 0) {
|
||||
if (nb === 2) nb = 0;else self.lastNeed = nb - 3;
|
||||
}
|
||||
return nb;
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
|
||||
// Validates as many continuation bytes for a multi-byte UTF-8 character as
|
||||
// needed or are available. If we see a non-continuation byte where we expect
|
||||
// one, we "replace" the validated continuation bytes we've seen so far with
|
||||
// UTF-8 replacement characters ('\ufffd'), to match v8's UTF-8 decoding
|
||||
// behavior. The continuation byte check is included three times in the case
|
||||
// where all of the continuation bytes for a character exist in the same buffer.
|
||||
// It is also done this way as a slight performance increase instead of using a
|
||||
// loop.
|
||||
function utf8CheckExtraBytes(self, buf, p) {
|
||||
if ((buf[0] & 0xC0) !== 0x80) {
|
||||
self.lastNeed = 0;
|
||||
return '\ufffd'.repeat(p);
|
||||
}
|
||||
if (self.lastNeed > 1 && buf.length > 1) {
|
||||
if ((buf[1] & 0xC0) !== 0x80) {
|
||||
self.lastNeed = 1;
|
||||
return '\ufffd'.repeat(p + 1);
|
||||
}
|
||||
if (self.lastNeed > 2 && buf.length > 2) {
|
||||
if ((buf[2] & 0xC0) !== 0x80) {
|
||||
self.lastNeed = 2;
|
||||
return '\ufffd'.repeat(p + 2);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Attempts to complete a multi-byte UTF-8 character using bytes from a Buffer.
|
||||
function utf8FillLast(buf) {
|
||||
var p = this.lastTotal - this.lastNeed;
|
||||
var r = utf8CheckExtraBytes(this, buf, p);
|
||||
if (r !== undefined) return r;
|
||||
if (this.lastNeed <= buf.length) {
|
||||
buf.copy(this.lastChar, p, 0, this.lastNeed);
|
||||
return this.lastChar.toString(this.encoding, 0, this.lastTotal);
|
||||
}
|
||||
buf.copy(this.lastChar, p, 0, buf.length);
|
||||
this.lastNeed -= buf.length;
|
||||
}
|
||||
|
||||
// Returns all complete UTF-8 characters in a Buffer. If the Buffer ended on a
|
||||
// partial character, the character's bytes are buffered until the required
|
||||
// number of bytes are available.
|
||||
function utf8Text(buf, i) {
|
||||
var total = utf8CheckIncomplete(this, buf, i);
|
||||
if (!this.lastNeed) return buf.toString('utf8', i);
|
||||
this.lastTotal = total;
|
||||
var end = buf.length - (total - this.lastNeed);
|
||||
buf.copy(this.lastChar, 0, end);
|
||||
return buf.toString('utf8', i, end);
|
||||
}
|
||||
|
||||
// For UTF-8, a replacement character for each buffered byte of a (partial)
|
||||
// character needs to be added to the output.
|
||||
function utf8End(buf) {
|
||||
var r = buf && buf.length ? this.write(buf) : '';
|
||||
if (this.lastNeed) return r + '\ufffd'.repeat(this.lastTotal - this.lastNeed);
|
||||
return r;
|
||||
}
|
||||
|
||||
// UTF-16LE typically needs two bytes per character, but even if we have an even
|
||||
// number of bytes available, we need to check if we end on a leading/high
|
||||
// surrogate. In that case, we need to wait for the next two bytes in order to
|
||||
// decode the last character properly.
|
||||
function utf16Text(buf, i) {
|
||||
if ((buf.length - i) % 2 === 0) {
|
||||
var r = buf.toString('utf16le', i);
|
||||
if (r) {
|
||||
var c = r.charCodeAt(r.length - 1);
|
||||
if (c >= 0xD800 && c <= 0xDBFF) {
|
||||
this.lastNeed = 2;
|
||||
this.lastTotal = 4;
|
||||
this.lastChar[0] = buf[buf.length - 2];
|
||||
this.lastChar[1] = buf[buf.length - 1];
|
||||
return r.slice(0, -1);
|
||||
}
|
||||
}
|
||||
return r;
|
||||
}
|
||||
this.lastNeed = 1;
|
||||
this.lastTotal = 2;
|
||||
this.lastChar[0] = buf[buf.length - 1];
|
||||
return buf.toString('utf16le', i, buf.length - 1);
|
||||
}
|
||||
|
||||
// For UTF-16LE we do not explicitly append special replacement characters if we
|
||||
// end on a partial character, we simply let v8 handle that.
|
||||
function utf16End(buf) {
|
||||
var r = buf && buf.length ? this.write(buf) : '';
|
||||
if (this.lastNeed) {
|
||||
var end = this.lastTotal - this.lastNeed;
|
||||
return r + this.lastChar.toString('utf16le', 0, end);
|
||||
}
|
||||
return r;
|
||||
}
|
||||
|
||||
function base64Text(buf, i) {
|
||||
var n = (buf.length - i) % 3;
|
||||
if (n === 0) return buf.toString('base64', i);
|
||||
this.lastNeed = 3 - n;
|
||||
this.lastTotal = 3;
|
||||
if (n === 1) {
|
||||
this.lastChar[0] = buf[buf.length - 1];
|
||||
} else {
|
||||
this.lastChar[0] = buf[buf.length - 2];
|
||||
this.lastChar[1] = buf[buf.length - 1];
|
||||
}
|
||||
return buf.toString('base64', i, buf.length - n);
|
||||
}
|
||||
|
||||
function base64End(buf) {
|
||||
var r = buf && buf.length ? this.write(buf) : '';
|
||||
if (this.lastNeed) return r + this.lastChar.toString('base64', 0, 3 - this.lastNeed);
|
||||
return r;
|
||||
}
|
||||
|
||||
// Pass bytes on through for single-byte encodings (e.g. ascii, latin1, hex)
|
||||
function simpleWrite(buf) {
|
||||
return buf.toString(this.encoding);
|
||||
}
|
||||
|
||||
function simpleEnd(buf) {
|
||||
return buf && buf.length ? this.write(buf) : '';
|
||||
}
|
||||
95
node_modules/readdirp/node_modules/string_decoder/package.json
generated
vendored
Normal file
95
node_modules/readdirp/node_modules/string_decoder/package.json
generated
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "string_decoder@~1.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "string_decoder",
|
||||
"name": "string_decoder",
|
||||
"rawSpec": "~1.0.0",
|
||||
"spec": ">=1.0.0 <1.1.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp\\node_modules\\readable-stream"
|
||||
]
|
||||
],
|
||||
"_from": "string_decoder@>=1.0.0 <1.1.0",
|
||||
"_id": "string_decoder@1.0.0",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp/string_decoder",
|
||||
"_nodeVersion": "7.8.0",
|
||||
"_npmOperationalInternal": {
|
||||
"host": "packages-18-east.internal.npmjs.com",
|
||||
"tmp": "tmp/string_decoder-1.0.0.tgz_1491485897373_0.9406327686738223"
|
||||
},
|
||||
"_npmUser": {
|
||||
"name": "rvagg",
|
||||
"email": "rod@vagg.org"
|
||||
},
|
||||
"_npmVersion": "4.4.4",
|
||||
"_phantomChildren": {},
|
||||
"_requested": {
|
||||
"raw": "string_decoder@~1.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "string_decoder",
|
||||
"name": "string_decoder",
|
||||
"rawSpec": "~1.0.0",
|
||||
"spec": ">=1.0.0 <1.1.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/readdirp/readable-stream"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/string_decoder/-/string_decoder-1.0.0.tgz",
|
||||
"_shasum": "f06f41157b664d86069f84bdbdc9b0d8ab281667",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "string_decoder@~1.0.0",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\readdirp\\node_modules\\readable-stream",
|
||||
"bugs": {
|
||||
"url": "https://github.com/rvagg/string_decoder/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"buffer-shims": "~1.0.0"
|
||||
},
|
||||
"description": "The string_decoder module from Node core",
|
||||
"devDependencies": {
|
||||
"babel-polyfill": "^6.23.0",
|
||||
"tap": "~0.4.8"
|
||||
},
|
||||
"directories": {},
|
||||
"dist": {
|
||||
"shasum": "f06f41157b664d86069f84bdbdc9b0d8ab281667",
|
||||
"tarball": "https://registry.npmjs.org/string_decoder/-/string_decoder-1.0.0.tgz"
|
||||
},
|
||||
"gitHead": "847f2f513a5648857af03adf680c90d833a499d2",
|
||||
"homepage": "https://github.com/rvagg/string_decoder",
|
||||
"keywords": [
|
||||
"string",
|
||||
"decoder",
|
||||
"browser",
|
||||
"browserify"
|
||||
],
|
||||
"license": "MIT",
|
||||
"main": "lib/string_decoder.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "substack",
|
||||
"email": "mail@substack.net"
|
||||
},
|
||||
{
|
||||
"name": "rvagg",
|
||||
"email": "rod@vagg.org"
|
||||
}
|
||||
],
|
||||
"name": "string_decoder",
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/rvagg/string_decoder.git"
|
||||
},
|
||||
"scripts": {
|
||||
"test": "tap test/parallel/*.js"
|
||||
},
|
||||
"version": "1.0.0"
|
||||
}
|
||||
121
node_modules/readdirp/package.json
generated
vendored
Normal file
121
node_modules/readdirp/package.json
generated
vendored
Normal file
@@ -0,0 +1,121 @@
|
||||
{
|
||||
"_args": [
|
||||
[
|
||||
{
|
||||
"raw": "readdirp@^2.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "readdirp",
|
||||
"name": "readdirp",
|
||||
"rawSpec": "^2.0.0",
|
||||
"spec": ">=2.0.0 <3.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\chokidar"
|
||||
]
|
||||
],
|
||||
"_from": "readdirp@>=2.0.0 <3.0.0",
|
||||
"_id": "readdirp@2.1.0",
|
||||
"_inCache": true,
|
||||
"_location": "/readdirp",
|
||||
"_nodeVersion": "4.4.6",
|
||||
"_npmOperationalInternal": {
|
||||
"host": "packages-16-east.internal.npmjs.com",
|
||||
"tmp": "tmp/readdirp-2.1.0.tgz_1467053820730_0.8782131769694388"
|
||||
},
|
||||
"_npmUser": {
|
||||
"name": "thlorenz",
|
||||
"email": "thlorenz@gmx.de"
|
||||
},
|
||||
"_npmVersion": "2.15.6",
|
||||
"_phantomChildren": {
|
||||
"brace-expansion": "1.1.7",
|
||||
"buffer-shims": "1.0.0",
|
||||
"core-util-is": "1.0.2",
|
||||
"inherits": "2.0.3",
|
||||
"process-nextick-args": "1.0.7",
|
||||
"util-deprecate": "1.0.2"
|
||||
},
|
||||
"_requested": {
|
||||
"raw": "readdirp@^2.0.0",
|
||||
"scope": null,
|
||||
"escapedName": "readdirp",
|
||||
"name": "readdirp",
|
||||
"rawSpec": "^2.0.0",
|
||||
"spec": ">=2.0.0 <3.0.0",
|
||||
"type": "range"
|
||||
},
|
||||
"_requiredBy": [
|
||||
"/chokidar"
|
||||
],
|
||||
"_resolved": "https://registry.npmjs.org/readdirp/-/readdirp-2.1.0.tgz",
|
||||
"_shasum": "4ed0ad060df3073300c48440373f72d1cc642d78",
|
||||
"_shrinkwrap": null,
|
||||
"_spec": "readdirp@^2.0.0",
|
||||
"_where": "C:\\Users\\chvra\\Documents\\angular-play\\nodeRest\\node_modules\\chokidar",
|
||||
"author": {
|
||||
"name": "Thorsten Lorenz",
|
||||
"email": "thlorenz@gmx.de",
|
||||
"url": "thlorenz.com"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/thlorenz/readdirp/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"graceful-fs": "^4.1.2",
|
||||
"minimatch": "^3.0.2",
|
||||
"readable-stream": "^2.0.2",
|
||||
"set-immediate-shim": "^1.0.1"
|
||||
},
|
||||
"description": "Recursive version of fs.readdir with streaming api.",
|
||||
"devDependencies": {
|
||||
"nave": "^0.5.1",
|
||||
"proxyquire": "^1.7.9",
|
||||
"tap": "1.3.2",
|
||||
"through2": "^2.0.0"
|
||||
},
|
||||
"directories": {},
|
||||
"dist": {
|
||||
"shasum": "4ed0ad060df3073300c48440373f72d1cc642d78",
|
||||
"tarball": "https://registry.npmjs.org/readdirp/-/readdirp-2.1.0.tgz"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=0.6"
|
||||
},
|
||||
"gitHead": "5a3751f86a1c2bbbb8e3a42685d4191992631e6c",
|
||||
"homepage": "https://github.com/thlorenz/readdirp",
|
||||
"keywords": [
|
||||
"recursive",
|
||||
"fs",
|
||||
"stream",
|
||||
"streams",
|
||||
"readdir",
|
||||
"filesystem",
|
||||
"find",
|
||||
"filter"
|
||||
],
|
||||
"license": "MIT",
|
||||
"main": "readdirp.js",
|
||||
"maintainers": [
|
||||
{
|
||||
"name": "thlorenz",
|
||||
"email": "thlorenz@gmx.de"
|
||||
}
|
||||
],
|
||||
"name": "readdirp",
|
||||
"optionalDependencies": {},
|
||||
"readme": "ERROR: No README data found!",
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git://github.com/thlorenz/readdirp.git"
|
||||
},
|
||||
"scripts": {
|
||||
"test": "if [ -e $TRAVIS ]; then npm run test-all; else npm run test-main; fi",
|
||||
"test-0.10": "nave use 0.10 npm run test-main",
|
||||
"test-0.12": "nave use 0.12 npm run test-main",
|
||||
"test-4": "nave use 4.4 npm run test-main",
|
||||
"test-6": "nave use 6.2 npm run test-main",
|
||||
"test-all": "npm run test-main && npm run test-0.10 && npm run test-0.12 && npm run test-4 && npm run test-6",
|
||||
"test-main": "(cd test && set -e; for t in ./*.js; do node $t; done)"
|
||||
},
|
||||
"version": "2.1.0"
|
||||
}
|
||||
300
node_modules/readdirp/readdirp.js
generated
vendored
Normal file
300
node_modules/readdirp/readdirp.js
generated
vendored
Normal file
@@ -0,0 +1,300 @@
|
||||
'use strict';
|
||||
|
||||
var fs = require('graceful-fs')
|
||||
, path = require('path')
|
||||
, minimatch = require('minimatch')
|
||||
, toString = Object.prototype.toString
|
||||
, si = require('set-immediate-shim')
|
||||
;
|
||||
|
||||
|
||||
// Standard helpers
|
||||
function isFunction (obj) {
|
||||
return toString.call(obj) === '[object Function]';
|
||||
}
|
||||
|
||||
function isString (obj) {
|
||||
return toString.call(obj) === '[object String]';
|
||||
}
|
||||
|
||||
function isRegExp (obj) {
|
||||
return toString.call(obj) === '[object RegExp]';
|
||||
}
|
||||
|
||||
function isUndefined (obj) {
|
||||
return obj === void 0;
|
||||
}
|
||||
|
||||
/**
|
||||
* Main function which ends up calling readdirRec and reads all files and directories in given root recursively.
|
||||
* @param { Object } opts Options to specify root (start directory), filters and recursion depth
|
||||
* @param { function } callback1 When callback2 is given calls back for each processed file - function (fileInfo) { ... },
|
||||
* when callback2 is not given, it behaves like explained in callback2
|
||||
* @param { function } callback2 Calls back once all files have been processed with an array of errors and file infos
|
||||
* function (err, fileInfos) { ... }
|
||||
*/
|
||||
function readdir(opts, callback1, callback2) {
|
||||
var stream
|
||||
, handleError
|
||||
, handleFatalError
|
||||
, pending = 0
|
||||
, errors = []
|
||||
, readdirResult = {
|
||||
directories: []
|
||||
, files: []
|
||||
}
|
||||
, fileProcessed
|
||||
, allProcessed
|
||||
, realRoot
|
||||
, aborted = false
|
||||
, paused = false
|
||||
;
|
||||
|
||||
// If no callbacks were given we will use a streaming interface
|
||||
if (isUndefined(callback1)) {
|
||||
var api = require('./stream-api')();
|
||||
stream = api.stream;
|
||||
callback1 = api.processEntry;
|
||||
callback2 = api.done;
|
||||
handleError = api.handleError;
|
||||
handleFatalError = api.handleFatalError;
|
||||
|
||||
stream.on('close', function () { aborted = true; });
|
||||
stream.on('pause', function () { paused = true; });
|
||||
stream.on('resume', function () { paused = false; });
|
||||
} else {
|
||||
handleError = function (err) { errors.push(err); };
|
||||
handleFatalError = function (err) {
|
||||
handleError(err);
|
||||
allProcessed(errors, null);
|
||||
};
|
||||
}
|
||||
|
||||
if (isUndefined(opts)){
|
||||
handleFatalError(new Error (
|
||||
'Need to pass at least one argument: opts! \n' +
|
||||
'https://github.com/thlorenz/readdirp#options'
|
||||
)
|
||||
);
|
||||
return stream;
|
||||
}
|
||||
|
||||
opts.root = opts.root || '.';
|
||||
opts.fileFilter = opts.fileFilter || function() { return true; };
|
||||
opts.directoryFilter = opts.directoryFilter || function() { return true; };
|
||||
opts.depth = typeof opts.depth === 'undefined' ? 999999999 : opts.depth;
|
||||
opts.entryType = opts.entryType || 'files';
|
||||
|
||||
var statfn = opts.lstat === true ? fs.lstat.bind(fs) : fs.stat.bind(fs);
|
||||
|
||||
if (isUndefined(callback2)) {
|
||||
fileProcessed = function() { };
|
||||
allProcessed = callback1;
|
||||
} else {
|
||||
fileProcessed = callback1;
|
||||
allProcessed = callback2;
|
||||
}
|
||||
|
||||
function normalizeFilter (filter) {
|
||||
|
||||
if (isUndefined(filter)) return undefined;
|
||||
|
||||
function isNegated (filters) {
|
||||
|
||||
function negated(f) {
|
||||
return f.indexOf('!') === 0;
|
||||
}
|
||||
|
||||
var some = filters.some(negated);
|
||||
if (!some) {
|
||||
return false;
|
||||
} else {
|
||||
if (filters.every(negated)) {
|
||||
return true;
|
||||
} else {
|
||||
// if we detect illegal filters, bail out immediately
|
||||
throw new Error(
|
||||
'Cannot mix negated with non negated glob filters: ' + filters + '\n' +
|
||||
'https://github.com/thlorenz/readdirp#filters'
|
||||
);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Turn all filters into a function
|
||||
if (isFunction(filter)) {
|
||||
|
||||
return filter;
|
||||
|
||||
} else if (isString(filter)) {
|
||||
|
||||
return function (entryInfo) {
|
||||
return minimatch(entryInfo.name, filter.trim());
|
||||
};
|
||||
|
||||
} else if (filter && Array.isArray(filter)) {
|
||||
|
||||
if (filter) filter = filter.map(function (f) {
|
||||
return f.trim();
|
||||
});
|
||||
|
||||
return isNegated(filter) ?
|
||||
// use AND to concat multiple negated filters
|
||||
function (entryInfo) {
|
||||
return filter.every(function (f) {
|
||||
return minimatch(entryInfo.name, f);
|
||||
});
|
||||
}
|
||||
:
|
||||
// use OR to concat multiple inclusive filters
|
||||
function (entryInfo) {
|
||||
return filter.some(function (f) {
|
||||
return minimatch(entryInfo.name, f);
|
||||
});
|
||||
};
|
||||
}
|
||||
}
|
||||
|
||||
function processDir(currentDir, entries, callProcessed) {
|
||||
if (aborted) return;
|
||||
var total = entries.length
|
||||
, processed = 0
|
||||
, entryInfos = []
|
||||
;
|
||||
|
||||
fs.realpath(currentDir, function(err, realCurrentDir) {
|
||||
if (aborted) return;
|
||||
if (err) {
|
||||
handleError(err);
|
||||
callProcessed(entryInfos);
|
||||
return;
|
||||
}
|
||||
|
||||
var relDir = path.relative(realRoot, realCurrentDir);
|
||||
|
||||
if (entries.length === 0) {
|
||||
callProcessed([]);
|
||||
} else {
|
||||
entries.forEach(function (entry) {
|
||||
|
||||
var fullPath = path.join(realCurrentDir, entry)
|
||||
, relPath = path.join(relDir, entry);
|
||||
|
||||
statfn(fullPath, function (err, stat) {
|
||||
if (err) {
|
||||
handleError(err);
|
||||
} else {
|
||||
entryInfos.push({
|
||||
name : entry
|
||||
, path : relPath // relative to root
|
||||
, fullPath : fullPath
|
||||
|
||||
, parentDir : relDir // relative to root
|
||||
, fullParentDir : realCurrentDir
|
||||
|
||||
, stat : stat
|
||||
});
|
||||
}
|
||||
processed++;
|
||||
if (processed === total) callProcessed(entryInfos);
|
||||
});
|
||||
});
|
||||
}
|
||||
});
|
||||
}
|
||||
|
||||
function readdirRec(currentDir, depth, callCurrentDirProcessed) {
|
||||
var args = arguments;
|
||||
if (aborted) return;
|
||||
if (paused) {
|
||||
si(function () {
|
||||
readdirRec.apply(null, args);
|
||||
})
|
||||
return;
|
||||
}
|
||||
|
||||
fs.readdir(currentDir, function (err, entries) {
|
||||
if (err) {
|
||||
handleError(err);
|
||||
callCurrentDirProcessed();
|
||||
return;
|
||||
}
|
||||
|
||||
processDir(currentDir, entries, function(entryInfos) {
|
||||
|
||||
var subdirs = entryInfos
|
||||
.filter(function (ei) { return ei.stat.isDirectory() && opts.directoryFilter(ei); });
|
||||
|
||||
subdirs.forEach(function (di) {
|
||||
if(opts.entryType === 'directories' || opts.entryType === 'both' || opts.entryType === 'all') {
|
||||
fileProcessed(di);
|
||||
}
|
||||
readdirResult.directories.push(di);
|
||||
});
|
||||
|
||||
entryInfos
|
||||
.filter(function(ei) {
|
||||
var isCorrectType = opts.entryType === 'all' ?
|
||||
!ei.stat.isDirectory() : ei.stat.isFile() || ei.stat.isSymbolicLink();
|
||||
return isCorrectType && opts.fileFilter(ei);
|
||||
})
|
||||
.forEach(function (fi) {
|
||||
if(opts.entryType === 'files' || opts.entryType === 'both' || opts.entryType === 'all') {
|
||||
fileProcessed(fi);
|
||||
}
|
||||
readdirResult.files.push(fi);
|
||||
});
|
||||
|
||||
var pendingSubdirs = subdirs.length;
|
||||
|
||||
// Be done if no more subfolders exist or we reached the maximum desired depth
|
||||
if(pendingSubdirs === 0 || depth === opts.depth) {
|
||||
callCurrentDirProcessed();
|
||||
} else {
|
||||
// recurse into subdirs, keeping track of which ones are done
|
||||
// and call back once all are processed
|
||||
subdirs.forEach(function (subdir) {
|
||||
readdirRec(subdir.fullPath, depth + 1, function () {
|
||||
pendingSubdirs = pendingSubdirs - 1;
|
||||
if(pendingSubdirs === 0) {
|
||||
callCurrentDirProcessed();
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
});
|
||||
});
|
||||
}
|
||||
|
||||
// Validate and normalize filters
|
||||
try {
|
||||
opts.fileFilter = normalizeFilter(opts.fileFilter);
|
||||
opts.directoryFilter = normalizeFilter(opts.directoryFilter);
|
||||
} catch (err) {
|
||||
// if we detect illegal filters, bail out immediately
|
||||
handleFatalError(err);
|
||||
return stream;
|
||||
}
|
||||
|
||||
// If filters were valid get on with the show
|
||||
fs.realpath(opts.root, function(err, res) {
|
||||
if (err) {
|
||||
handleFatalError(err);
|
||||
return stream;
|
||||
}
|
||||
|
||||
realRoot = res;
|
||||
readdirRec(opts.root, 0, function () {
|
||||
// All errors are collected into the errors array
|
||||
if (errors.length > 0) {
|
||||
allProcessed(errors, readdirResult);
|
||||
} else {
|
||||
allProcessed(null, readdirResult);
|
||||
}
|
||||
});
|
||||
});
|
||||
|
||||
return stream;
|
||||
}
|
||||
|
||||
module.exports = readdir;
|
||||
99
node_modules/readdirp/stream-api.js
generated
vendored
Normal file
99
node_modules/readdirp/stream-api.js
generated
vendored
Normal file
@@ -0,0 +1,99 @@
|
||||
'use strict';
|
||||
|
||||
var si = require('set-immediate-shim');
|
||||
var stream = require('readable-stream');
|
||||
var util = require('util');
|
||||
|
||||
var Readable = stream.Readable;
|
||||
|
||||
module.exports = ReaddirpReadable;
|
||||
|
||||
util.inherits(ReaddirpReadable, Readable);
|
||||
|
||||
function ReaddirpReadable (opts) {
|
||||
if (!(this instanceof ReaddirpReadable)) return new ReaddirpReadable(opts);
|
||||
|
||||
opts = opts || {};
|
||||
|
||||
opts.objectMode = true;
|
||||
Readable.call(this, opts);
|
||||
|
||||
// backpressure not implemented at this point
|
||||
this.highWaterMark = Infinity;
|
||||
|
||||
this._destroyed = false;
|
||||
this._paused = false;
|
||||
this._warnings = [];
|
||||
this._errors = [];
|
||||
|
||||
this._pauseResumeErrors();
|
||||
}
|
||||
|
||||
var proto = ReaddirpReadable.prototype;
|
||||
|
||||
proto._pauseResumeErrors = function () {
|
||||
var self = this;
|
||||
self.on('pause', function () { self._paused = true });
|
||||
self.on('resume', function () {
|
||||
if (self._destroyed) return;
|
||||
self._paused = false;
|
||||
|
||||
self._warnings.forEach(function (err) { self.emit('warn', err) });
|
||||
self._warnings.length = 0;
|
||||
|
||||
self._errors.forEach(function (err) { self.emit('error', err) });
|
||||
self._errors.length = 0;
|
||||
})
|
||||
}
|
||||
|
||||
// called for each entry
|
||||
proto._processEntry = function (entry) {
|
||||
if (this._destroyed) return;
|
||||
this.push(entry);
|
||||
}
|
||||
|
||||
proto._read = function () { }
|
||||
|
||||
proto.destroy = function () {
|
||||
// when stream is destroyed it will emit nothing further, not even errors or warnings
|
||||
this.push(null);
|
||||
this.readable = false;
|
||||
this._destroyed = true;
|
||||
this.emit('close');
|
||||
}
|
||||
|
||||
proto._done = function () {
|
||||
this.push(null);
|
||||
}
|
||||
|
||||
// we emit errors and warnings async since we may handle errors like invalid args
|
||||
// within the initial event loop before any event listeners subscribed
|
||||
proto._handleError = function (err) {
|
||||
var self = this;
|
||||
si(function () {
|
||||
if (self._paused) return self._warnings.push(err);
|
||||
if (!self._destroyed) self.emit('warn', err);
|
||||
});
|
||||
}
|
||||
|
||||
proto._handleFatalError = function (err) {
|
||||
var self = this;
|
||||
si(function () {
|
||||
if (self._paused) return self._errors.push(err);
|
||||
if (!self._destroyed) self.emit('error', err);
|
||||
});
|
||||
}
|
||||
|
||||
function createStreamAPI () {
|
||||
var stream = new ReaddirpReadable();
|
||||
|
||||
return {
|
||||
stream : stream
|
||||
, processEntry : stream._processEntry.bind(stream)
|
||||
, done : stream._done.bind(stream)
|
||||
, handleError : stream._handleError.bind(stream)
|
||||
, handleFatalError : stream._handleFatalError.bind(stream)
|
||||
};
|
||||
}
|
||||
|
||||
module.exports = createStreamAPI;
|
||||
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file3.ext3
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_file3.ext3
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_subdir1/root1_dir1_subdir1_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir1/root_dir1_subdir1/root1_dir1_subdir1_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir2/root_dir2_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir2/root_dir2_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir2/root_dir2_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_dir2/root_dir2_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file1.ext1
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file2.ext2
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file3.ext3
generated
vendored
Normal file
0
node_modules/readdirp/test/bed/root_file3.ext3
generated
vendored
Normal file
338
node_modules/readdirp/test/readdirp-stream.js
generated
vendored
Normal file
338
node_modules/readdirp/test/readdirp-stream.js
generated
vendored
Normal file
@@ -0,0 +1,338 @@
|
||||
/*jshint asi:true */
|
||||
|
||||
var debug //= true;
|
||||
var test = debug ? function () {} : require('tap').test
|
||||
var test_ = !debug ? function () {} : require('tap').test
|
||||
, path = require('path')
|
||||
, fs = require('fs')
|
||||
, util = require('util')
|
||||
, TransformStream = require('readable-stream').Transform
|
||||
, through = require('through2')
|
||||
, proxyquire = require('proxyquire')
|
||||
, streamapi = require('../stream-api')
|
||||
, readdirp = require('..')
|
||||
, root = path.join(__dirname, 'bed')
|
||||
, totalDirs = 6
|
||||
, totalFiles = 12
|
||||
, ext1Files = 4
|
||||
, ext2Files = 3
|
||||
, ext3Files = 2
|
||||
;
|
||||
|
||||
// see test/readdirp.js for test bed layout
|
||||
|
||||
function opts (extend) {
|
||||
var o = { root: root };
|
||||
|
||||
if (extend) {
|
||||
for (var prop in extend) {
|
||||
o[prop] = extend[prop];
|
||||
}
|
||||
}
|
||||
return o;
|
||||
}
|
||||
|
||||
function capture () {
|
||||
var result = { entries: [], errors: [], ended: false }
|
||||
, dst = new TransformStream({ objectMode: true });
|
||||
|
||||
dst._transform = function (entry, _, cb) {
|
||||
result.entries.push(entry);
|
||||
cb();
|
||||
}
|
||||
|
||||
dst._flush = function (cb) {
|
||||
result.ended = true;
|
||||
this.push(result);
|
||||
cb();
|
||||
}
|
||||
|
||||
return dst;
|
||||
}
|
||||
|
||||
test('\nintegrated', function (t) {
|
||||
t.test('\n# reading root without filter', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts())
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, totalFiles, 'emits all files');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
));
|
||||
})
|
||||
|
||||
t.test('\n# normal: ["*.ext1", "*.ext3"]', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { fileFilter: [ '*.ext1', '*.ext3' ] } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, ext1Files + ext3Files, 'all ext1 and ext3 files');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# files only', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { entryType: 'files' } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, totalFiles, 'returned files');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# directories only', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { entryType: 'directories' } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, totalDirs, 'returned directories');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# both directories + files', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { entryType: 'both' } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, totalDirs + totalFiles, 'returned everything');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# directory filter with directories only', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { entryType: 'directories', directoryFilter: [ 'root_dir1', '*dir1_subdir1' ] } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, 2, 'two directories');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# directory and file filters with both entries', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { entryType: 'both', directoryFilter: [ 'root_dir1', '*dir1_subdir1' ], fileFilter: [ '!*.ext1' ] } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, 6, '2 directories and 4 files');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
cb();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# negated: ["!*.ext1", "!*.ext3"]', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
readdirp(opts( { fileFilter: [ '!*.ext1', '!*.ext3' ] } ))
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.pipe(capture())
|
||||
.pipe(through.obj(
|
||||
function (result, _ , cb) {
|
||||
t.equals(result.entries.length, totalFiles - ext1Files - ext3Files, 'all but ext1 and ext3 files');
|
||||
t.ok(result.ended, 'ends stream');
|
||||
t.end();
|
||||
}
|
||||
))
|
||||
})
|
||||
|
||||
t.test('\n# no options given', function (t) {
|
||||
t.plan(1);
|
||||
readdirp()
|
||||
.on('error', function (err) {
|
||||
t.similar(err.toString() , /Need to pass at least one argument/ , 'emits meaningful error');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
t.test('\n# mixed: ["*.ext1", "!*.ext3"]', function (t) {
|
||||
t.plan(1);
|
||||
|
||||
readdirp(opts( { fileFilter: [ '*.ext1', '!*.ext3' ] } ))
|
||||
.on('error', function (err) {
|
||||
t.similar(err.toString() , /Cannot mix negated with non negated glob filters/ , 'emits meaningful error');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
|
||||
test('\napi separately', function (t) {
|
||||
|
||||
t.test('\n# handleError', function (t) {
|
||||
t.plan(1);
|
||||
|
||||
var api = streamapi()
|
||||
, warning = new Error('some file caused problems');
|
||||
|
||||
api.stream
|
||||
.on('warn', function (err) {
|
||||
t.equals(err, warning, 'warns with the handled error');
|
||||
})
|
||||
api.handleError(warning);
|
||||
})
|
||||
|
||||
t.test('\n# when stream is paused and then resumed', function (t) {
|
||||
t.plan(6);
|
||||
var api = streamapi()
|
||||
, resumed = false
|
||||
, fatalError = new Error('fatal!')
|
||||
, nonfatalError = new Error('nonfatal!')
|
||||
, processedData = 'some data'
|
||||
;
|
||||
|
||||
api.stream
|
||||
.on('warn', function (err) {
|
||||
t.equals(err, nonfatalError, 'emits the buffered warning');
|
||||
t.ok(resumed, 'emits warning only after it was resumed');
|
||||
})
|
||||
.on('error', function (err) {
|
||||
t.equals(err, fatalError, 'emits the buffered fatal error');
|
||||
t.ok(resumed, 'emits errors only after it was resumed');
|
||||
})
|
||||
.on('data', function (data) {
|
||||
t.equals(data, processedData, 'emits the buffered data');
|
||||
t.ok(resumed, 'emits data only after it was resumed');
|
||||
})
|
||||
.pause()
|
||||
|
||||
api.processEntry(processedData);
|
||||
api.handleError(nonfatalError);
|
||||
api.handleFatalError(fatalError);
|
||||
|
||||
setTimeout(function () {
|
||||
resumed = true;
|
||||
api.stream.resume();
|
||||
}, 1)
|
||||
})
|
||||
|
||||
t.test('\n# when a stream is paused it stops walking the fs', function (t) {
|
||||
var resumed = false,
|
||||
mockedAPI = streamapi();
|
||||
|
||||
mockedAPI.processEntry = function (entry) {
|
||||
if (!resumed) t.notOk(true, 'should not emit while paused')
|
||||
t.ok(entry, 'emitted while resumed')
|
||||
}.bind(mockedAPI.stream)
|
||||
|
||||
function wrapper () {
|
||||
return mockedAPI
|
||||
}
|
||||
|
||||
var readdirp = proxyquire('../readdirp', {'./stream-api': wrapper})
|
||||
, stream = readdirp(opts())
|
||||
.on('error', function (err) {
|
||||
t.fail('should not throw error', err);
|
||||
})
|
||||
.on('end', function () {
|
||||
t.end()
|
||||
})
|
||||
.pause();
|
||||
|
||||
setTimeout(function () {
|
||||
resumed = true;
|
||||
stream.resume();
|
||||
}, 5)
|
||||
})
|
||||
|
||||
t.test('\n# when a stream is destroyed, it emits "closed", but no longer emits "data", "warn" and "error"', function (t) {
|
||||
var api = streamapi()
|
||||
, fatalError = new Error('fatal!')
|
||||
, nonfatalError = new Error('nonfatal!')
|
||||
, processedData = 'some data'
|
||||
, plan = 0;
|
||||
|
||||
t.plan(6)
|
||||
var stream = api.stream
|
||||
.on('warn', function (err) {
|
||||
t.ok(!stream._destroyed, 'emits warning until destroyed');
|
||||
})
|
||||
.on('error', function (err) {
|
||||
t.ok(!stream._destroyed, 'emits errors until destroyed');
|
||||
})
|
||||
.on('data', function (data) {
|
||||
t.ok(!stream._destroyed, 'emits data until destroyed');
|
||||
})
|
||||
.on('close', function () {
|
||||
t.ok(stream._destroyed, 'emits close when stream is destroyed');
|
||||
})
|
||||
|
||||
|
||||
api.processEntry(processedData);
|
||||
api.handleError(nonfatalError);
|
||||
api.handleFatalError(fatalError);
|
||||
|
||||
setTimeout(function () {
|
||||
stream.destroy()
|
||||
|
||||
t.notOk(stream.readable, 'stream is no longer readable after it is destroyed')
|
||||
|
||||
api.processEntry(processedData);
|
||||
api.handleError(nonfatalError);
|
||||
api.handleFatalError(fatalError);
|
||||
|
||||
process.nextTick(function () {
|
||||
t.pass('emits no more data, warn or error events after it was destroyed')
|
||||
t.end();
|
||||
})
|
||||
}, 10)
|
||||
})
|
||||
})
|
||||
289
node_modules/readdirp/test/readdirp.js
generated
vendored
Normal file
289
node_modules/readdirp/test/readdirp.js
generated
vendored
Normal file
@@ -0,0 +1,289 @@
|
||||
/*jshint asi:true */
|
||||
|
||||
var test = require('tap').test
|
||||
, path = require('path')
|
||||
, fs = require('fs')
|
||||
, util = require('util')
|
||||
, net = require('net')
|
||||
, readdirp = require('../readdirp.js')
|
||||
, root = path.join(__dirname, '../test/bed')
|
||||
, totalDirs = 6
|
||||
, totalFiles = 12
|
||||
, ext1Files = 4
|
||||
, ext2Files = 3
|
||||
, ext3Files = 2
|
||||
, rootDir2Files = 2
|
||||
, nameHasLength9Dirs = 2
|
||||
, depth1Files = 8
|
||||
, depth0Files = 3
|
||||
;
|
||||
|
||||
/*
|
||||
Structure of test bed:
|
||||
.
|
||||
├── root_dir1
|
||||
│ ├── root_dir1_file1.ext1
|
||||
│ ├── root_dir1_file2.ext2
|
||||
│ ├── root_dir1_file3.ext3
|
||||
│ ├── root_dir1_subdir1
|
||||
│ │ └── root1_dir1_subdir1_file1.ext1
|
||||
│ └── root_dir1_subdir2
|
||||
│ └── .gitignore
|
||||
├── root_dir2
|
||||
│ ├── root_dir2_file1.ext1
|
||||
│ ├── root_dir2_file2.ext2
|
||||
│ ├── root_dir2_subdir1
|
||||
│ │ └── .gitignore
|
||||
│ └── root_dir2_subdir2
|
||||
│ └── .gitignore
|
||||
├── root_file1.ext1
|
||||
├── root_file2.ext2
|
||||
└── root_file3.ext3
|
||||
|
||||
6 directories, 13 files
|
||||
*/
|
||||
|
||||
// console.log('\033[2J'); // clear console
|
||||
|
||||
function opts (extend) {
|
||||
var o = { root: root };
|
||||
|
||||
if (extend) {
|
||||
for (var prop in extend) {
|
||||
o[prop] = extend[prop];
|
||||
}
|
||||
}
|
||||
return o;
|
||||
}
|
||||
|
||||
test('\nreading root without filter', function (t) {
|
||||
t.plan(2);
|
||||
readdirp(opts(), function (err, res) {
|
||||
t.equals(res.directories.length, totalDirs, 'all directories');
|
||||
t.equals(res.files.length, totalFiles, 'all files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
test('\nreading root without filter using lstat', function (t) {
|
||||
t.plan(2);
|
||||
readdirp(opts({ lstat: true }), function (err, res) {
|
||||
t.equals(res.directories.length, totalDirs, 'all directories');
|
||||
t.equals(res.files.length, totalFiles, 'all files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
test('\nreading root with symlinks using lstat', function (t) {
|
||||
t.plan(2);
|
||||
fs.symlinkSync(path.join(root, 'root_dir1'), path.join(root, 'dirlink'));
|
||||
fs.symlinkSync(path.join(root, 'root_file1.ext1'), path.join(root, 'link.ext1'));
|
||||
readdirp(opts({ lstat: true }), function (err, res) {
|
||||
t.equals(res.directories.length, totalDirs, 'all directories');
|
||||
t.equals(res.files.length, totalFiles + 2, 'all files + symlinks');
|
||||
fs.unlinkSync(path.join(root, 'dirlink'));
|
||||
fs.unlinkSync(path.join(root, 'link.ext1'));
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
test('\nreading non-standard fds', function (t) {
|
||||
t.plan(2);
|
||||
var server = net.createServer().listen(path.join(root, 'test.sock'), function(){
|
||||
readdirp(opts({ entryType: 'all' }), function (err, res) {
|
||||
t.equals(res.files.length, totalFiles + 1, 'all files + socket');
|
||||
readdirp(opts({ entryType: 'both' }), function (err, res) {
|
||||
t.equals(res.files.length, totalFiles, 'all regular files only');
|
||||
server.close();
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
});
|
||||
})
|
||||
|
||||
test('\nreading root using glob filter', function (t) {
|
||||
// normal
|
||||
t.test('\n# "*.ext1"', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: '*.ext1' } ), function (err, res) {
|
||||
t.equals(res.files.length, ext1Files, 'all ext1 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
t.test('\n# ["*.ext1", "*.ext3"]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: [ '*.ext1', '*.ext3' ] } ), function (err, res) {
|
||||
t.equals(res.files.length, ext1Files + ext3Files, 'all ext1 and ext3 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
t.test('\n# "root_dir1"', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { directoryFilter: 'root_dir1' }), function (err, res) {
|
||||
t.equals(res.directories.length, 1, 'one directory');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
t.test('\n# ["root_dir1", "*dir1_subdir1"]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { directoryFilter: [ 'root_dir1', '*dir1_subdir1' ]}), function (err, res) {
|
||||
t.equals(res.directories.length, 2, 'two directories');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
t.test('\n# negated: "!*.ext1"', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: '!*.ext1' } ), function (err, res) {
|
||||
t.equals(res.files.length, totalFiles - ext1Files, 'all but ext1 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
t.test('\n# negated: ["!*.ext1", "!*.ext3"]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: [ '!*.ext1', '!*.ext3' ] } ), function (err, res) {
|
||||
t.equals(res.files.length, totalFiles - ext1Files - ext3Files, 'all but ext1 and ext3 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
t.test('\n# mixed: ["*.ext1", "!*.ext3"]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: [ '*.ext1', '!*.ext3' ] } ), function (err, res) {
|
||||
t.similar(err[0].toString(), /Cannot mix negated with non negated glob filters/, 'returns meaningfull error');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
t.test('\n# leading and trailing spaces: [" *.ext1", "*.ext3 "]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: [ ' *.ext1', '*.ext3 ' ] } ), function (err, res) {
|
||||
t.equals(res.files.length, ext1Files + ext3Files, 'all ext1 and ext3 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
t.test('\n# leading and trailing spaces: [" !*.ext1", " !*.ext3 "]', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: [ ' !*.ext1', ' !*.ext3' ] } ), function (err, res) {
|
||||
t.equals(res.files.length, totalFiles - ext1Files - ext3Files, 'all but ext1 and ext3 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
|
||||
t.test('\n# ** glob pattern', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { fileFilter: '**/*.ext1' } ), function (err, res) {
|
||||
t.equals(res.files.length, ext1Files, 'ignores ** in **/*.ext1 -> only *.ext1 files');
|
||||
t.end();
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
test('\n\nreading root using function filter', function (t) {
|
||||
t.test('\n# file filter -> "contains root_dir2"', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(
|
||||
opts( { fileFilter: function (fi) { return fi.name.indexOf('root_dir2') >= 0; } })
|
||||
, function (err, res) {
|
||||
t.equals(res.files.length, rootDir2Files, 'all rootDir2Files');
|
||||
t.end();
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
t.test('\n# directory filter -> "name has length 9"', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(
|
||||
opts( { directoryFilter: function (di) { return di.name.length === 9; } })
|
||||
, function (err, res) {
|
||||
t.equals(res.directories.length, nameHasLength9Dirs, 'all all dirs with name length 9');
|
||||
t.end();
|
||||
}
|
||||
)
|
||||
})
|
||||
})
|
||||
|
||||
test('\nreading root specifying maximum depth', function (t) {
|
||||
t.test('\n# depth 1', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { depth: 1 } ), function (err, res) {
|
||||
t.equals(res.files.length, depth1Files, 'does not return files at depth 2');
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
test('\nreading root with no recursion', function (t) {
|
||||
t.test('\n# depth 0', function (t) {
|
||||
t.plan(1);
|
||||
readdirp(opts( { depth: 0 } ), function (err, res) {
|
||||
t.equals(res.files.length, depth0Files, 'does not return files at depth 0');
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
test('\nprogress callbacks', function (t) {
|
||||
t.plan(2);
|
||||
|
||||
var pluckName = function(fi) { return fi.name; }
|
||||
, processedFiles = [];
|
||||
|
||||
readdirp(
|
||||
opts()
|
||||
, function(fi) {
|
||||
processedFiles.push(fi);
|
||||
}
|
||||
, function (err, res) {
|
||||
t.equals(processedFiles.length, res.files.length, 'calls back for each file processed');
|
||||
t.deepEquals(processedFiles.map(pluckName).sort(),res.files.map(pluckName).sort(), 'same file names');
|
||||
t.end();
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('resolving of name, full and relative paths', function (t) {
|
||||
var expected = {
|
||||
name : 'root_dir1_file1.ext1'
|
||||
, parentDirName : 'root_dir1'
|
||||
, path : 'root_dir1/root_dir1_file1.ext1'
|
||||
, fullPath : 'test/bed/root_dir1/root_dir1_file1.ext1'
|
||||
}
|
||||
, opts = [
|
||||
{ root: './bed' , prefix: '' }
|
||||
, { root: './bed/' , prefix: '' }
|
||||
, { root: 'bed' , prefix: '' }
|
||||
, { root: 'bed/' , prefix: '' }
|
||||
, { root: '../test/bed/' , prefix: '' }
|
||||
, { root: '.' , prefix: 'bed' }
|
||||
]
|
||||
t.plan(opts.length);
|
||||
|
||||
opts.forEach(function (op) {
|
||||
op.fileFilter = 'root_dir1_file1.ext1';
|
||||
|
||||
t.test('\n' + util.inspect(op), function (t) {
|
||||
t.plan(4);
|
||||
|
||||
readdirp (op, function(err, res) {
|
||||
t.equals(res.files[0].name, expected.name, 'correct name');
|
||||
t.equals(res.files[0].path, path.join(op.prefix, expected.path), 'correct path');
|
||||
})
|
||||
|
||||
fs.realpath(op.root, function(err, fullRoot) {
|
||||
readdirp (op, function(err, res) {
|
||||
t.equals(
|
||||
res.files[0].fullParentDir
|
||||
, path.join(fullRoot, op.prefix, expected.parentDirName)
|
||||
, 'correct parentDir'
|
||||
);
|
||||
t.equals(
|
||||
res.files[0].fullPath
|
||||
, path.join(fullRoot, op.prefix, expected.parentDirName, expected.name)
|
||||
, 'correct fullPath'
|
||||
);
|
||||
})
|
||||
})
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
|
||||
Reference in New Issue
Block a user